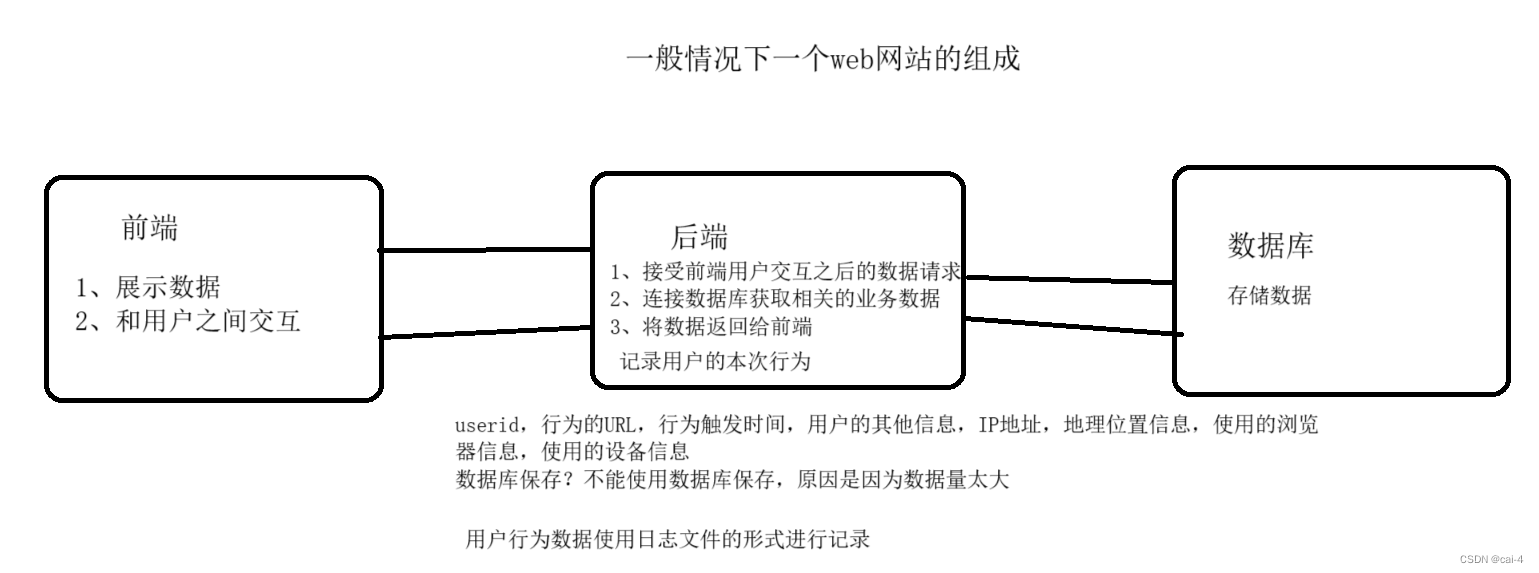
asp.net
html
spi
C语言数组实例
flex
云idea
node
web大学生网页作业成品
模板
vue3生命周期
PMP项目管理
素质模型
UI开发
分布式测温系统
Mybatis框架
Launcher定制
加密混淆
GO111MODULE=on
FusionCharts
服务监控重启
flume
2024/4/11 16:15:44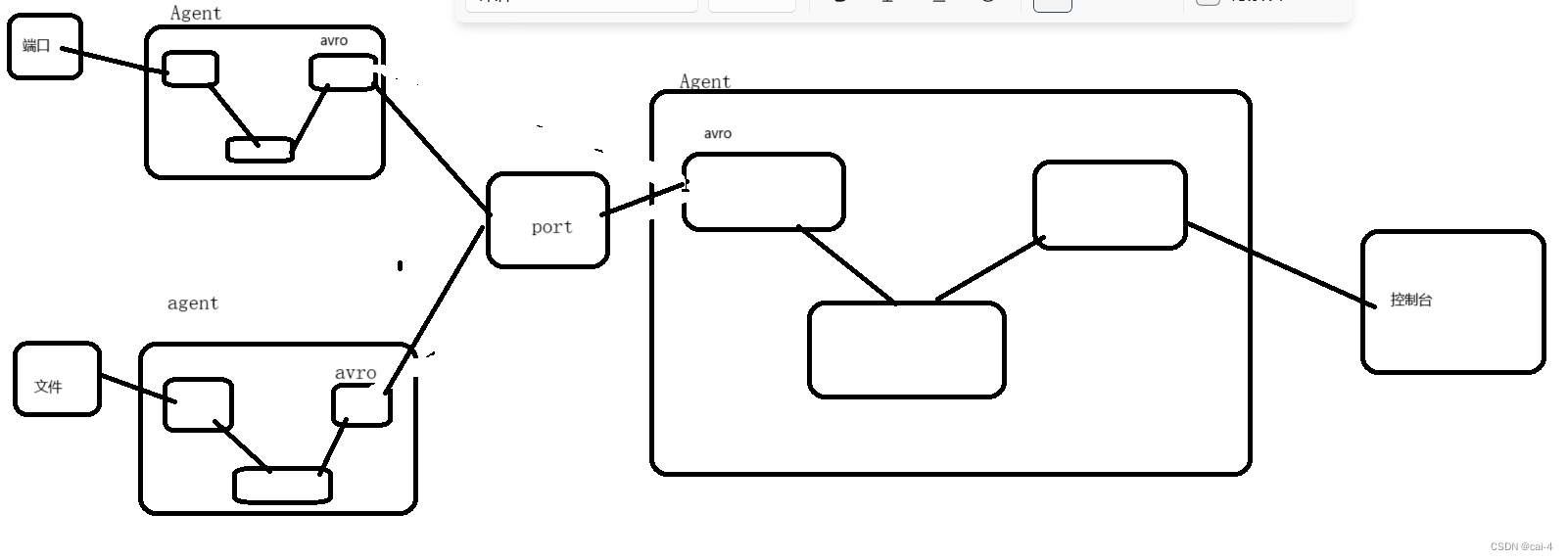
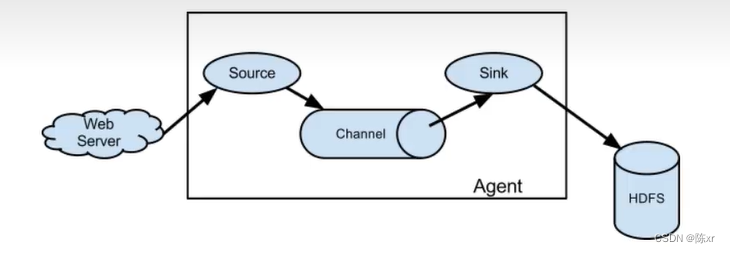
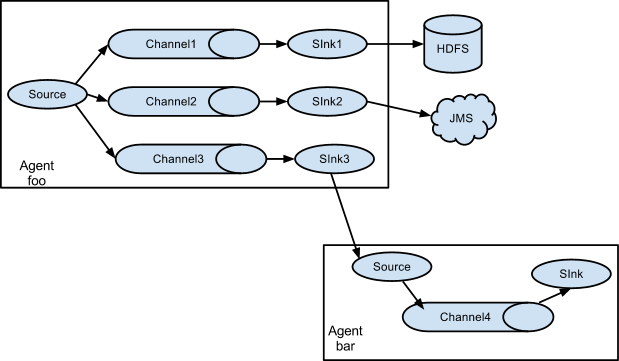
Flume架构以及应用介绍
在具体介绍本文内容之前,先给大家看一下Hadoop业务的整体开发流程: 从Hadoop的业务开发流程图中可以看出,在大数据的业务处理过程中,对于数据的采集是十分重要的一步,也是不可避免的一步,从而引出我们本…
2023_Spark_实验二十八:Flume部署及配置
实验目的:熟悉掌握Flume部署及配置
实验方法:通过在集群中部署Flume,掌握Flume配置
实验步骤:
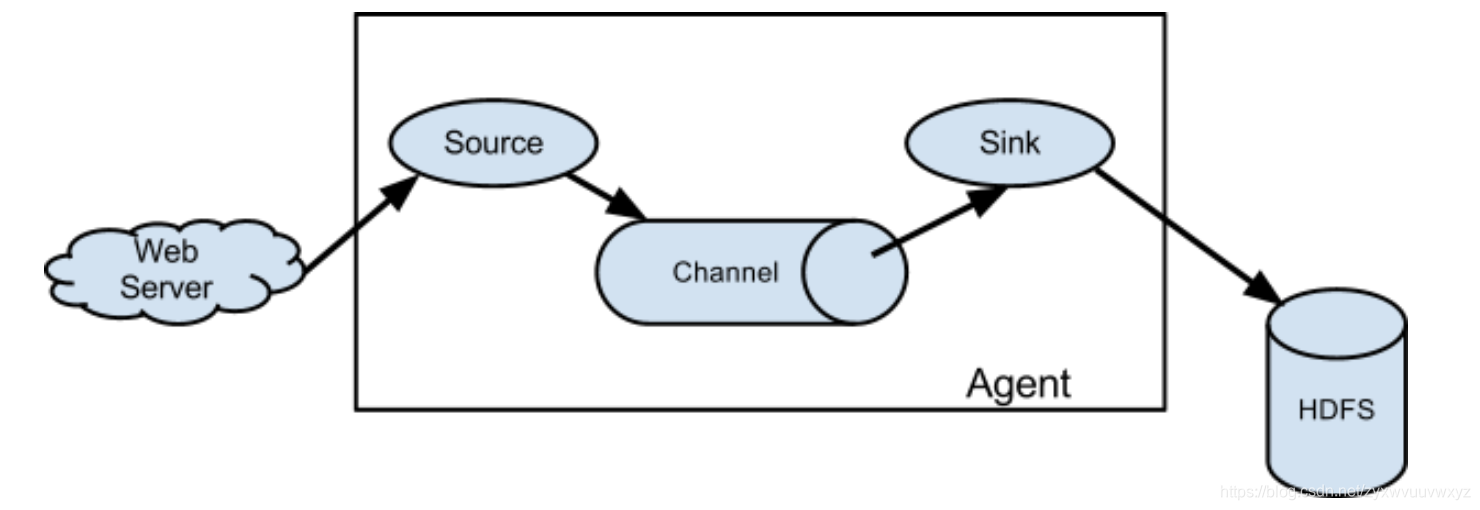
一、Flume简介
Flume是一种分布式的、可靠的和可用的服务,用于有效地收集、聚合和移动大量日志数据。它有一个简单灵活…

数据同步工具对比——SeaTunnel 、DataX、Sqoop、Flume、Flink CDC
在大数据时代,数据的采集、处理和分析变得尤为重要。业界出现了多种工具来帮助开发者和企业高效地处理数据流和数据集。本文将对比五种流行的数据处理工具:SeaTunnel、DataX、Sqoop、Flume和Flink CDC,从它们的设计理念、使用场景、优缺点等方…

Flume拦截器使用-实现分表、解决零点漂移等
1.场景分析
使用flume做数据传输时,可能遇到将一个数据流中的多张表分别保存到各自位置的问题,同时由于采集时间和数据实际发生时间存在差异,因此需要根据数据实际发生时间进行分区保存。 鉴于此,需要设计flume拦截器配置conf文件…

Flume基础知识(二):Flume安装部署
1. Flume 安装部署
1.1 安装地址
(1)Flume 官网地址:Welcome to Apache Flume — Apache Flume
(2)文档查看地址:Flume 1.11.0 User Guide — Apache Flume
(3)下载地址…
Flume内置拦截器与自定义拦截器(代码实战)
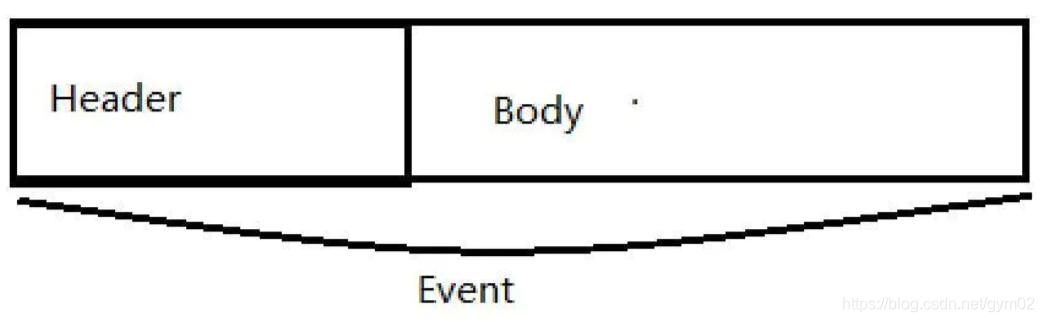
官网上内置拦截器的表 由于拦截器一般针对Event的Header进行处理,这里先介绍一下Event
event是flume中处理消息的基本单元,由零个或者多个header和body组成。Header 是 key/value 形式的,可以用来制造路由决策或携带其他结构化信息(如事件的…

Flume概念与其组件的分析和使用 (超详细)
概述
1.Flume的定义 Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。 Flume最主要的作用是,实时读取服务器本地磁盘的数据,将数据写入到HDFS。 …
Flume常用组件(Source,Channel,Sink)及其基本作用
Source组件类型
Netcat Source 接受来自于数据客户端的请求数据,常用于测试开发
Exec Source 运行一个给定的unix指令,将指令的执行结果作为数据来源
Spooling Directory Source 监视指定目录的新文件,并从出现的新文件中解析事件
Kafka …

flume【源码分析】分析Flume的拦截器
有的时候希望通过Flume将读取的文件再细分存储,比如讲source的数据按照业务类型分开存储,具体一点比如类似:将source中web、wap、media等的内容分开存储;比如丢弃或修改一些数据。这时可以考虑使用拦截器Interceptor。 flume通过拦…

Flume安装及使用
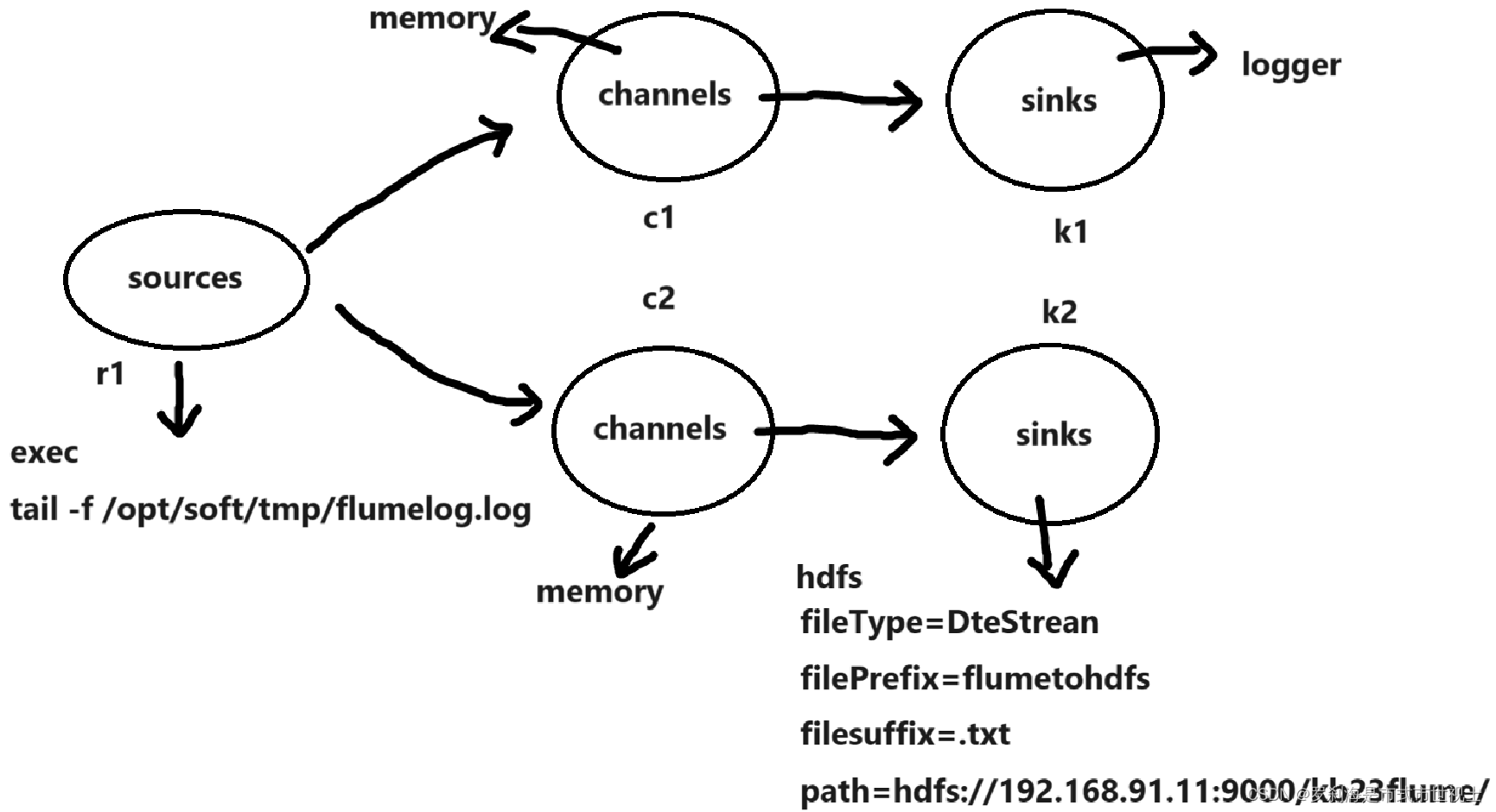
文章目录Flume安装及使用安装解压并改名配置flume.env.sh文件测试安装netcat安装telnet基本使用案例一配置conf文件运行案例二准备文件创建conf文件修改events.csv文件名运行文件:案例三 保存到HDFS新建conf文件:运行案例四 保存到Kafka新建conf文件运行…
Flume入门教程-简单案例
Flume入门教程-简单案例 1.下载安装 Java代码 官方网站:http://flume.apache.org/ http://mirror.bit.edu.cn/apache/flume/1.6.0/apache-flume-1.6.0-bin.tar.gz tar -zxvf apache-flume-1.6.0-bin.tar.gz 2.修改配置 重命名flume-conf.properties.template…
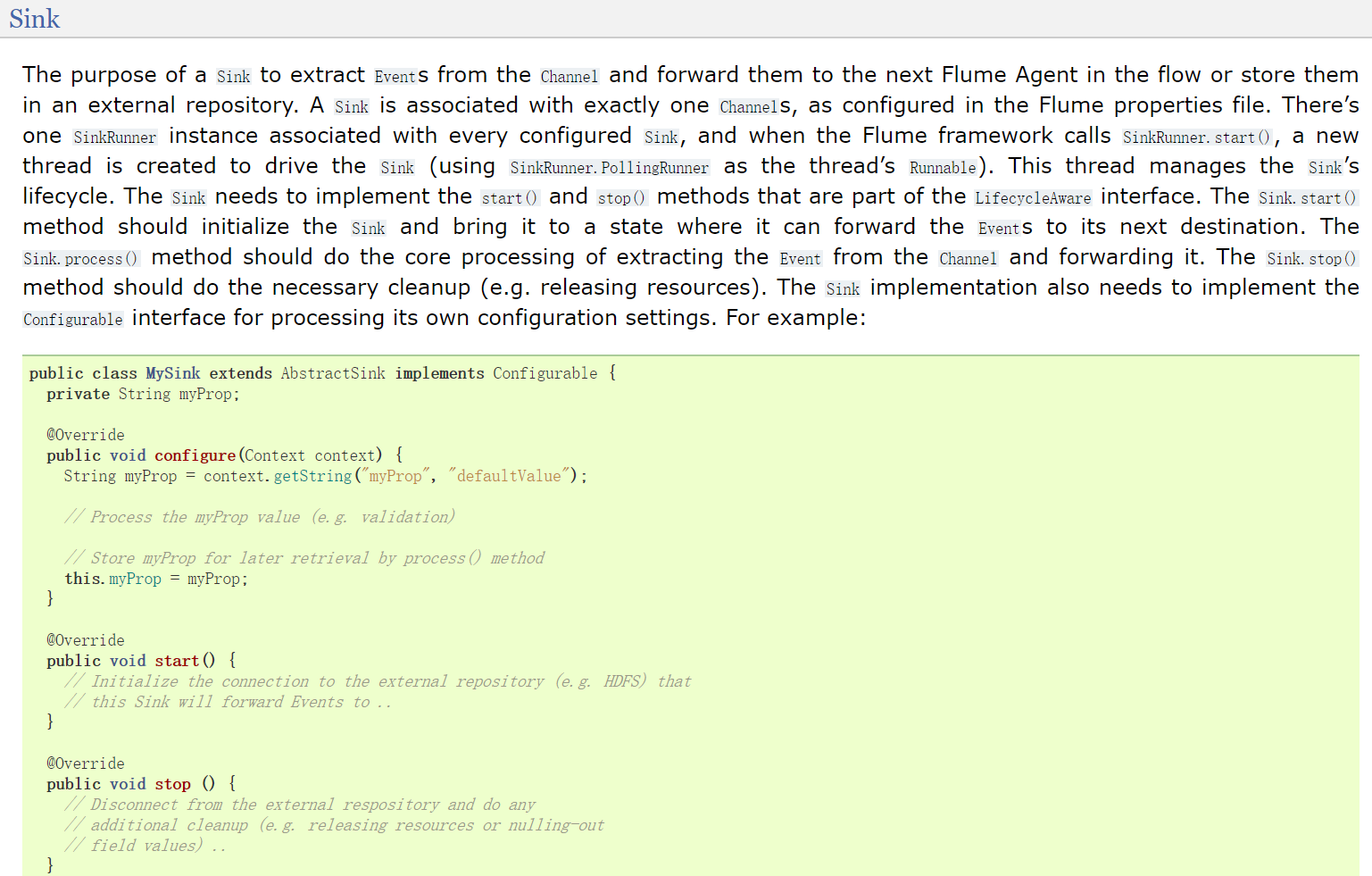
flume开发--自定义Sink
kafka可以通过自定义Sink的方式实现数据搜集并写入各种LOTP数据库,下面的例子是通过自定义Source实现数据写入分布式K-V数据库Aerospike. 1. 自定义Sink代码如下 [java] view plaincopy package kafka_sink.asd; import java.io.IOException; import java.ne…

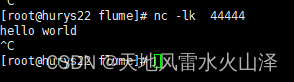
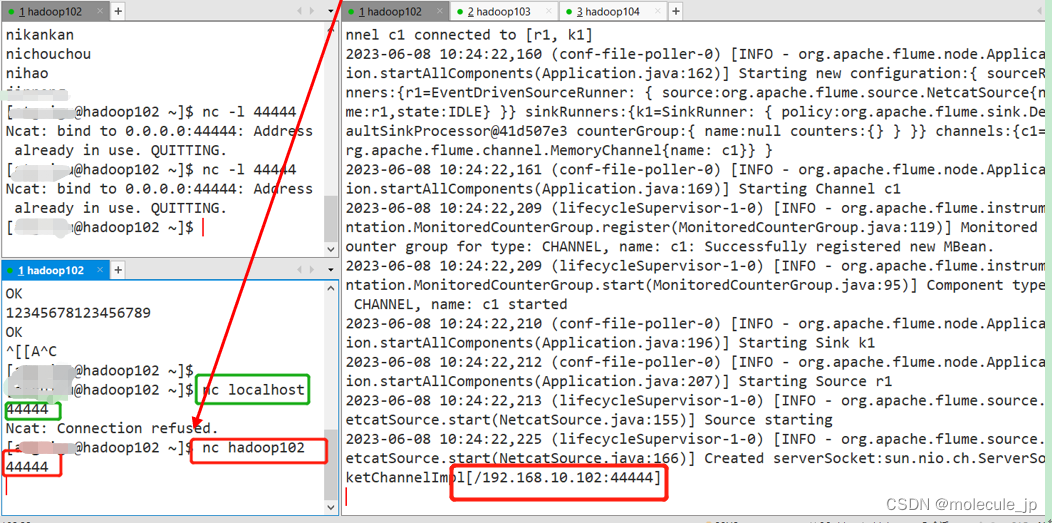
flume:Ncat: Connection refused.
一:nc -lk 44444 和 nc localhost 44444区别 nc -lk 44444 和 nc localhost 44444 是使用 nc 命令进行网络通信时的两种不同方式。 1. nc -lk 44444: - 这个命令表示在本地监听指定端口(44444)并接受传入的连接。 - -l 选项…
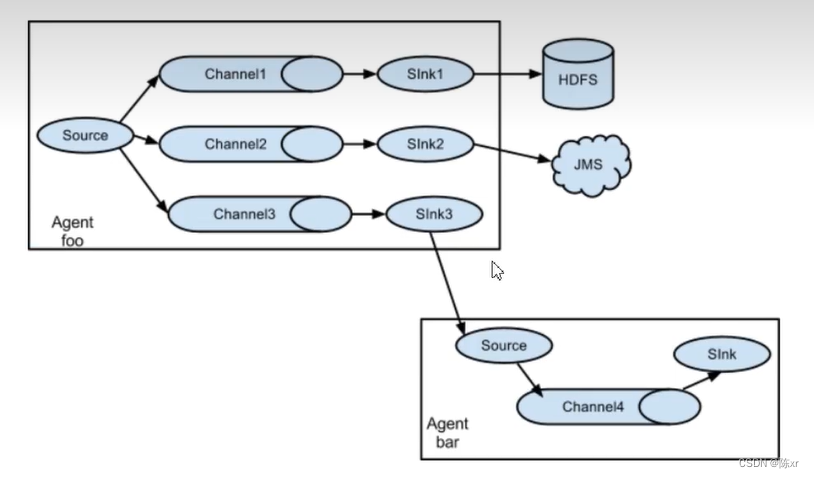
基于Flume的美团日志收集系统(一)架构和设计
美团的日志收集系统负责美团的所有业务日志的收集,并分别给Hadoop平台提供离线数据和Storm平台提供实时数据流。美团的日志收集系统基于Flume设计和搭建而成。 《基于Flume的美团日志收集系统》将分两部分给读者呈现美团日志收集系统的架构设计和实战经验。 第一部分…

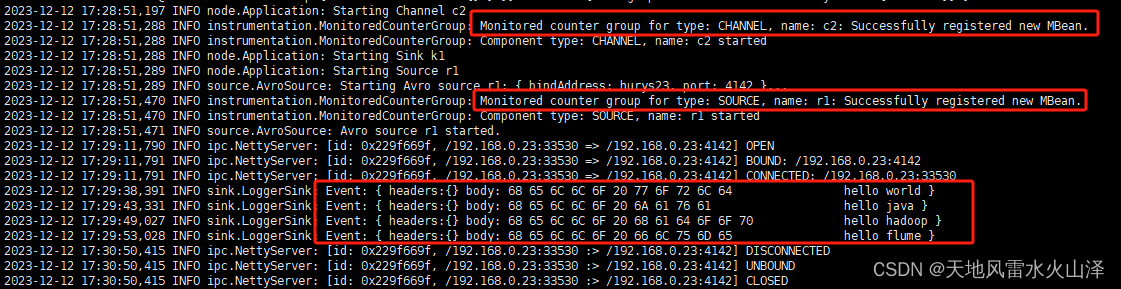
Flume的简单案例一 监听端口并读取数据
1)创建Flume Agent配置文件 flume-telnet-logger.conf 2)在配置文件中添加以下内容 参照https://flume.apache.org/FlumeUserGuide
[usernewbie job]$ cat flume-telnet-logger.conf
# example.conf: A single-node Flume configuration# Name the com…


Flume架构与源码分析-核心组件分析-1
首先所有核心组件都会实现org.apache.flume.lifecycle.LifecycleAware接口:
public interface LifecycleAware {public void start();public void stop();public LifecycleState getLifecycleState();
} start方法在整个Flume启动时或者初始化组件时都会调用start方…

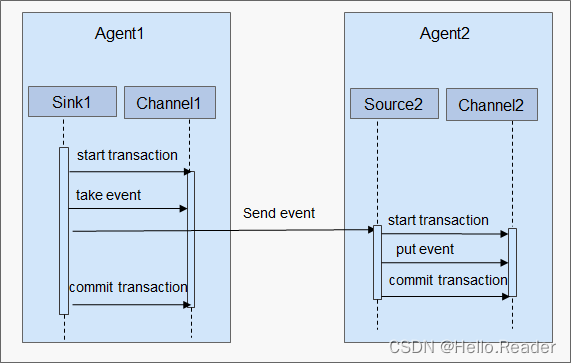
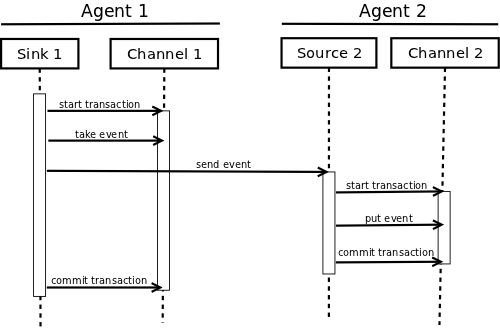
Flume数据传输事务分析
本文基于ThriftSource,MemoryChannel,HdfsSink三个组件,对Flume数据传输的事务进行分析,如果使用的是其他组件,Flume事务具体的处理方式将会不同。一般情况下,用MemoryChannel就好了,我们公司用的就是这个,…

Flume(ng) 自定义sink实现和属性注入
问题导读: 1.如何实现flume端自定一个sink,来按照我们的规则来保存日志? 2.想从flume的配置文件中获取rootPath的值,该如何配置? 最近需要利用flume来做收集远端日志,所以学习一些flume最基本的用法。…
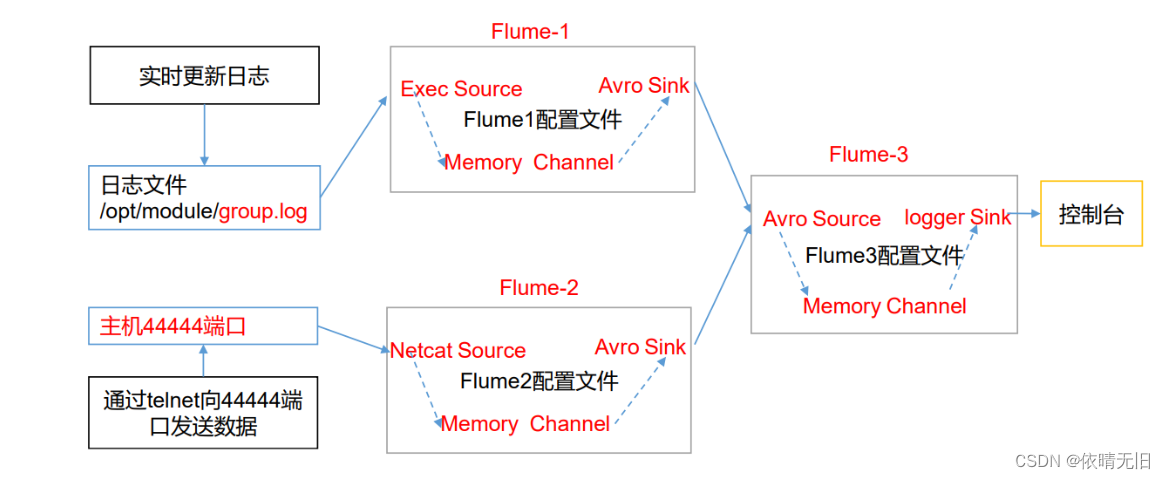
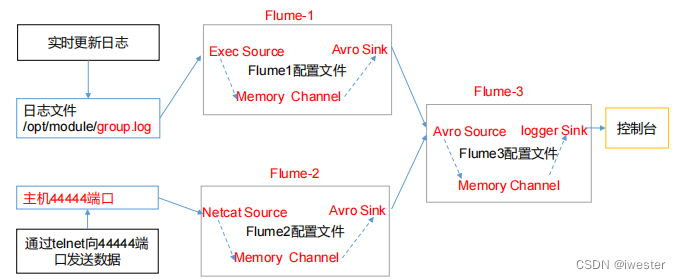
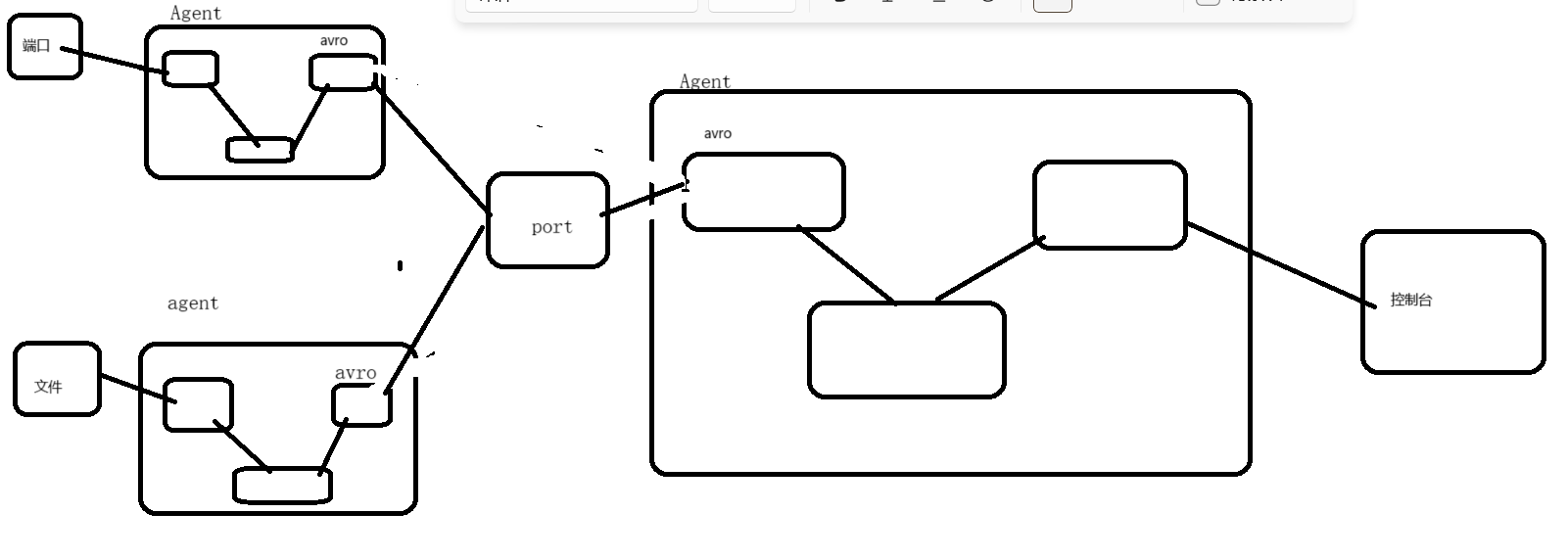
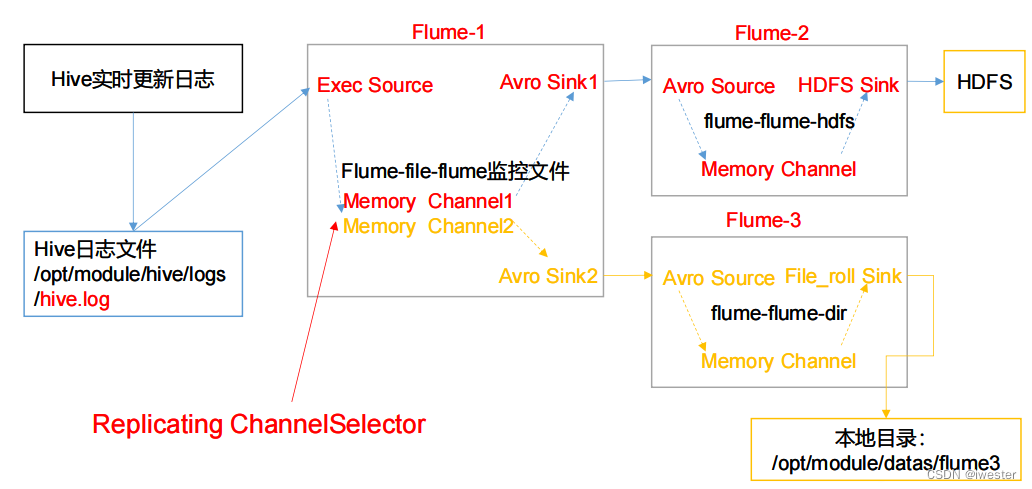
Flume基础知识(十):Flume 聚合实战
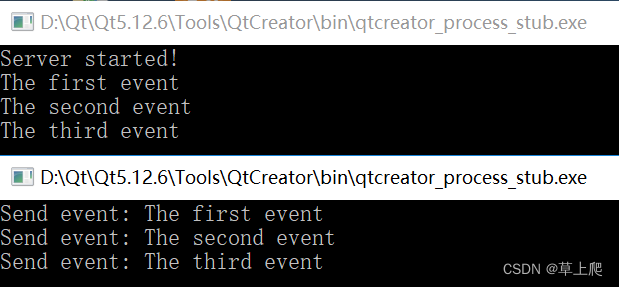
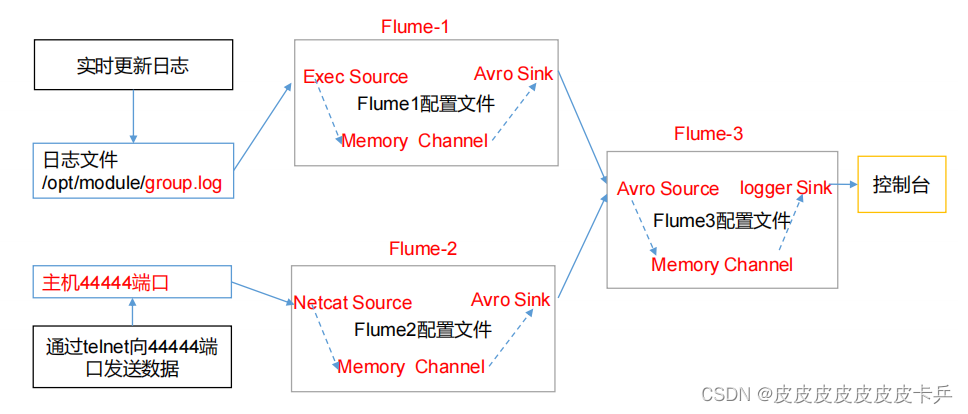
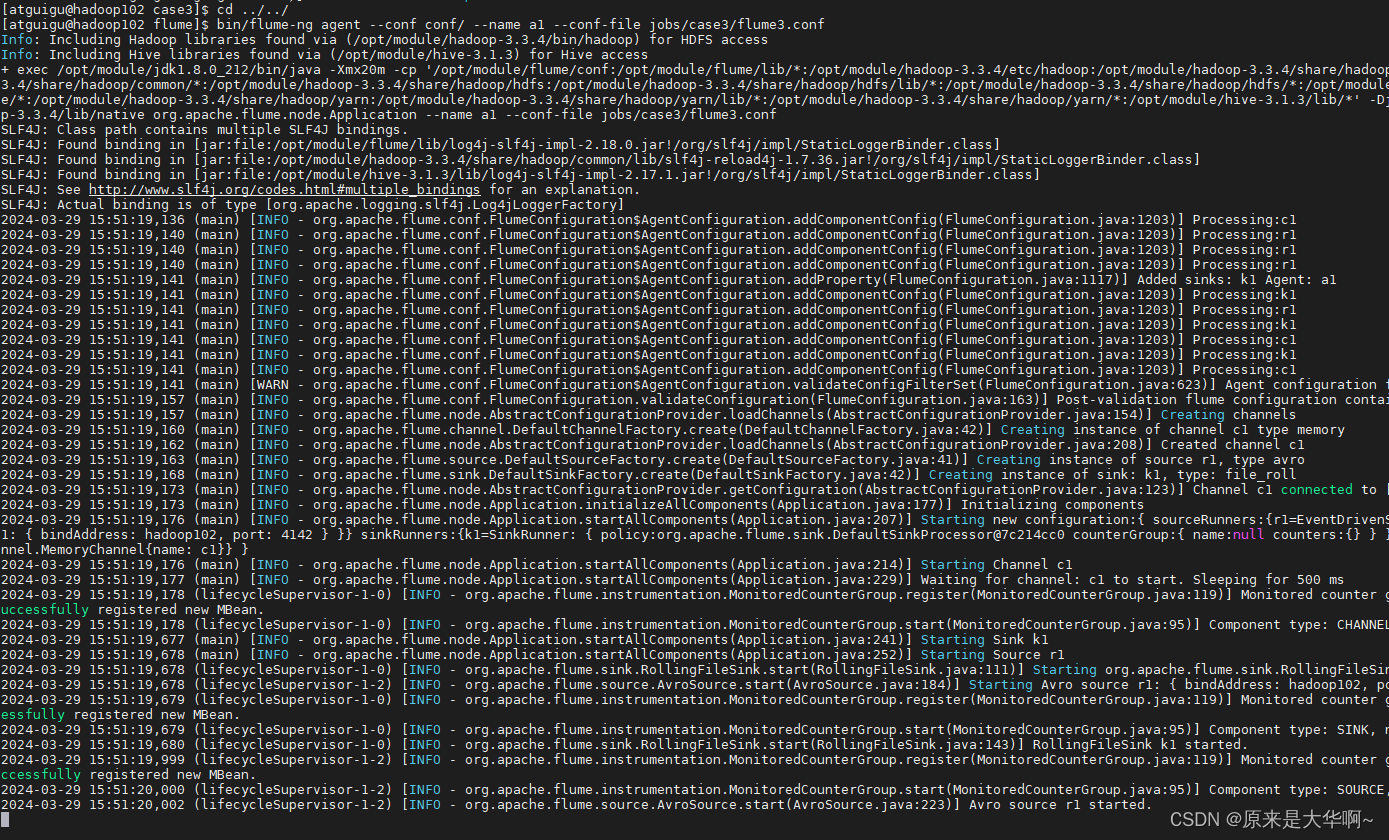
1)案例需求: hadoop100上的 Flume-1 监控文件/opt/module/group.log,
hadoop101上的 Flume-2 监控某一个端口的数据流,
Flume-1 与 Flume-2 将数据发送给 hadoop102 上的 Flume-3,Flume-3 将最终数据打印 到控制台。…

Flume中的拦截器的使用方法(Interceptor)
文章目录Flume中的拦截器的使用方法(Interceptor)Java代码实现打Jar 包创建conf文件验证Flume中的拦截器的使用方法(Interceptor)
Flume中的拦截器(interceptor),用户Source读取events发送到Sink的时候,在events header中加入一些…
Flume的简介以及安装配置
简介
Flume最初是Cloudera开发的,基于流式架构,灵活简单的,高可用高可靠的 实时日志采集,聚合和传输的系统,2011年10月22日Cloudera对Flume进行了里程碑式的改动,重构核心组件,核心配置以及代码…

数据采集工具之Flume的常用采集方式详细使用示例
数据采集工具之Flume的常用采集方式详细使用示例FlumeFlume概述Flume架构核心的组件常用Channel、Sink、Source类型Flume架构模式安装FlumeFlume的基本使用编写配置文件配置Agent实例各组件名称配置Source配置Channel配置Sink将source和sink绑定到channel启动Agent实例测试采集…
flume开发-自定义拦截器(Interceptor)
拦截器是简单的插件式组件,设置在source和channel之间。source接收到的时间,在写入channel之前,拦截器都可以进行转换或者删除这些事件。每个拦截器只处理同一个source接收到的事件。flume官方实现了很多拦截器也可以自定义拦截器。通过实现自…

flume taildirsource kafka chnanel hadf sink 配置文件
3台机器,2台 flume 往kafka里面采集,一台从kafka里面拿 放到hafs里面 第一台机器
大概是
#taildir source
#为各个组件命名
a1.sources r1
a1.channels c1
#声明source
a1.sources.r1.type TAILDIR
a1.sources.r1.filegroups f1
#监控的目录
a1.s…
flume介绍与原理(一)
1 .背景flume是由cloudera软件公司产出的可分布式日志收集系统,后与2009年被捐赠了apache软件基金会,为hadoop相关组件之一。尤其近几年随着flume的不断被完善以及升级版本的逐一推出,特别是flume-ng;同时flume内部的各种组件不断丰富&#x…
flume之退避算法backoff algorithm
flume之退避算法backoff algorithm什么是退避算法:In a single channel contention based medium access control (MAC) protocols, whenever more than one station or node tries to access the medium at the same instant of time, it leads to packet collisio…
GZ033 大数据应用开发赛题第02套
2023年全国职业院校技能大赛
赛题第02套 赛项名称: 大数据应用开发
英文名称: Big Data Application Development
赛项组别: 高等职业教育组
赛项编号: GZ033
背景描述
大数据时代背景下,电…

Flume中的拦截器(Interceptor)介绍与使用(一)
Flume中的拦截器(interceptor),用户Source读取events发送到Sink的时候,在events header中加入一些有用的信息,或者对events的内容进行过滤,完成初步的数据清洗。这在实际业务场景中非常有用,Flu…

用Kibana和logstash快速搭建实时日志查询、收集与分析系统
Logstash是一个完全开源的工具,他可以对你的日志进行收集、分析,并将其存储供以后使用(如,搜索),您可以使用它。说到搜索,logstash带有一个web界面,搜索和展示所有日志。 kibana 也是…
(二十)大数据实战——Flume数据采集的基本案例实战
前言
本节内容我们主要介绍几个Flume数据采集的基本案例,包括监控端口数据、实时监控单个追加文件、实时监控目录下多个新文件、实时监控目录下的多个追加文件等案例。完成flume数据监控的基本使用。
正文
监控端口数据 ①需求说明 - 使用 Flume 监听一个端口&am…
Flume性能测试报告
1. 测试环境 1.1 硬件 CPU:Intel(R) Core(TM) i7-6700 CPU 3.40GHz(8核)内存:16G 1.2 软件 Flume:1.6.0Hadoop:2.6.0-cdh5.5.0Kfaka:2.11-0.9.0.1JDK:1.8.0_91-b14 64位 1.3 测试文…

flume 拦截器(interceptor)
摘要: 拦截器是简单的插件式组件,设置在source和channel之间。source接收到的时间,在写入channel之前,拦截器都可以进行转换或者删除这些事件。每个拦截器只处理同一个source接收到的事件。可以自定义拦截器。 flume内置了很多拦截器…

Flume中的拦截器(Interceptor)介绍与使用(二)
Flume中的拦截器(interceptor),用户Source读取events发送到Sink的时候,在events header中加入一些有用的信息,或者对events的内容进行过滤,完成初步的数据清洗。这在实际业务场景中非常有用,Flu…

大数据组件-Flume集群环境的启动与验证
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇 个人主页:beixi 本文章收录于专栏(点击传送):【大数据学习】 💓💓持续更新中,感谢各位前辈朋友们支持…

CDH-Flume从Kafka同步数据到hive
启动Flume命令
flume-ng agent -n a -c /opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/lib/flume-ng/conf/ -f ./kafka2hiveTest.conf -Dflume.root.loggerINFO,console hive建表 语句
#分桶开启事务并分区
create table log_test(ip string,username string,reque…

Flume的简单案例二 读取本地文件
1)创建Flume Agent配置文件 flume-file-logger.conf 2)在配置文件中添加以下内容 参照https://flume.apache.org/FlumeUserGuide
# example.conf: A single-node Flume configuration# Name the components on this agent
a2.sources r2
a2.sinks k2
…

Flume学习---2、Flume进阶(事务)、负载均衡、故障转移、聚合
1、Flume进阶
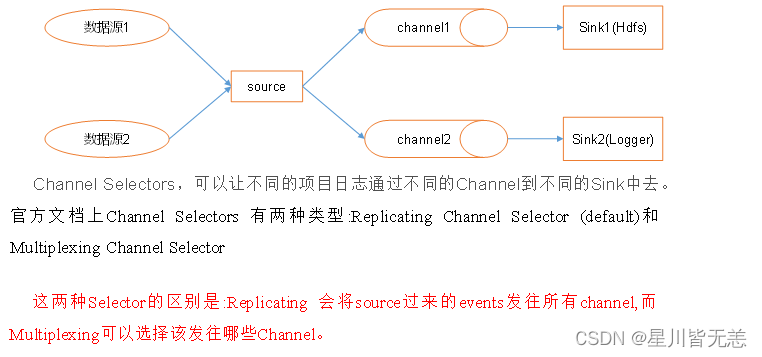
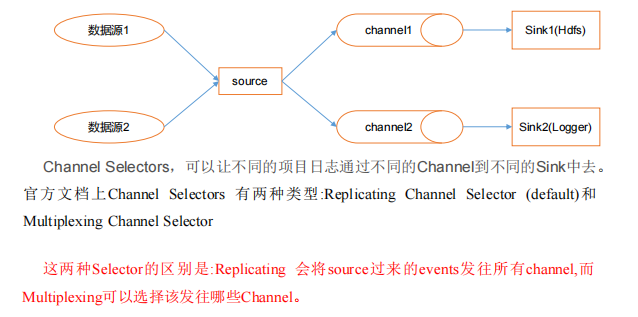
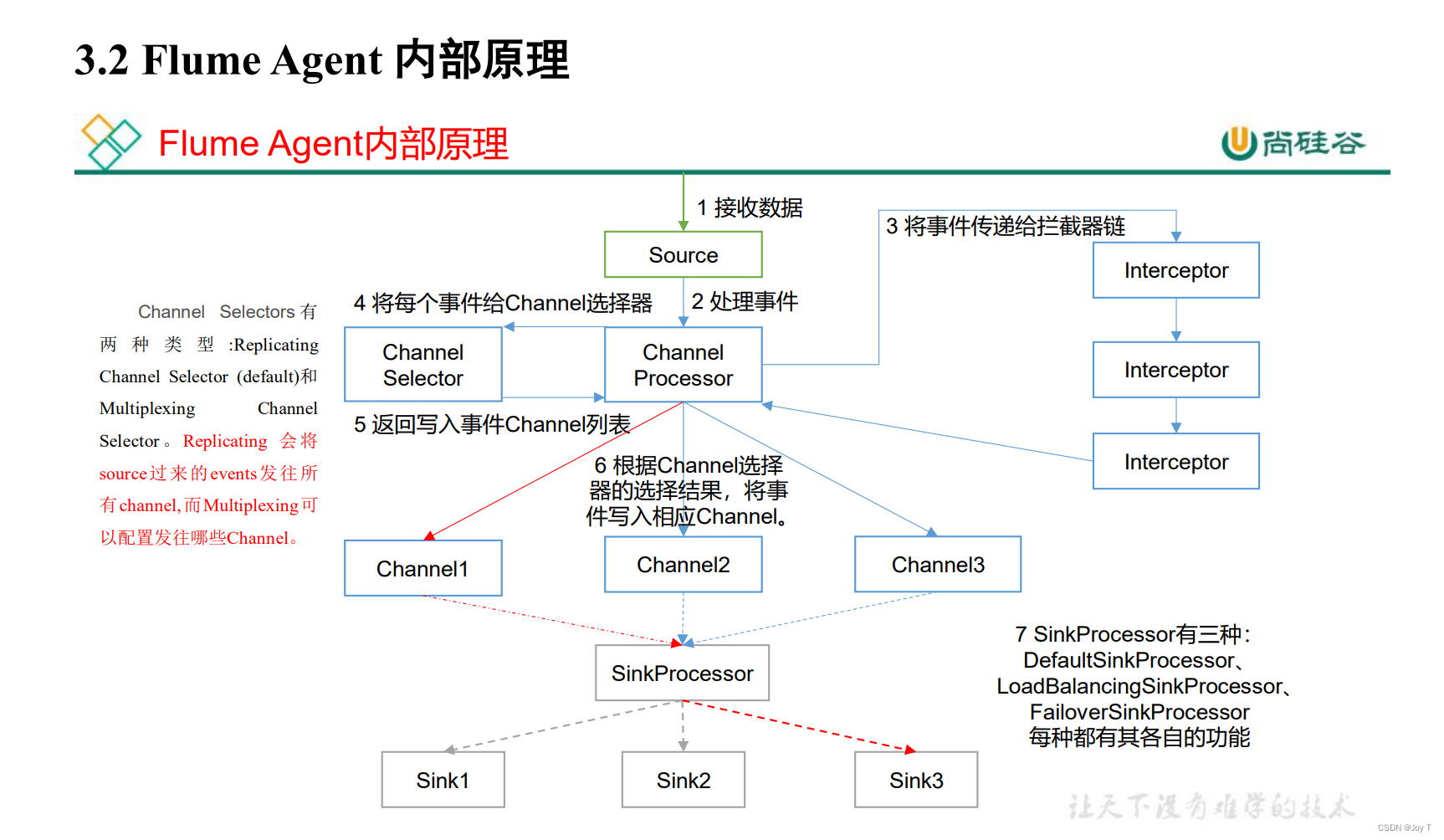
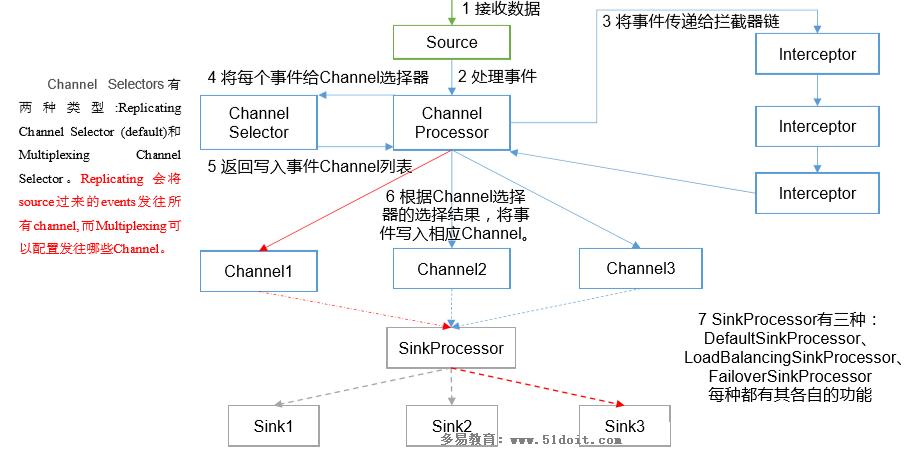
1.1 Flume事务 1.2 Flume Agent内存原理 1、ChannelSelector ChannelSelector的作用就是选出Event将要被发往哪个Channel。其共有两种类型,分别是Replicating(复制)和Multiplexing(多路复用)。 Replicat…
04数据平台Flume
Flume 功能 Flume主要作用,就是实时读取服务器本地磁盘数据,将数据写入到 HDFS。
Flume是 Cloudera提供的高可用,高可靠性,分布式的海量日志采集、聚合和传输的系统工具。
Flume 架构
Flume组成架构如下图所示:
A…
2024-02-07(Sqoop,Flume)
1.Sqoop的增量导入
实际工作中,数据的导入很多时候只需要导入增量的数据,并不需要将表中的数据每次都全部导入到hive或者hdfs中,因为这样会造成数据重复问题。
增量导入就是仅导入新添加到表中的行的技术。
sqoop支持两种模式的增量导入&a…
Hadoop学习笔记(HDP)-Part.20 安装Flume
目录 Part.01 关于HDP Part.02 核心组件原理 Part.03 资源规划 Part.04 基础环境配置 Part.05 Yum源配置 Part.06 安装OracleJDK Part.07 安装MySQL Part.08 部署Ambari集群 Part.09 安装OpenLDAP Part.10 创建集群 Part.11 安装Kerberos Part.12 安装HDFS Part.13 安装Ranger …

利用Flume拦截器(interceptors)实现Kafka Sink的自定义规则多分区写入
我们目前的业务场景如下:前端的5台日志收集服务器产生网站日志,使用Flume实时收集日志,并将日志发送至Kafka,然后Kafka中的日志一方面可以导入到HDFS,另一方面供实时计算模块使用。
前面的文章《Kafka分区机制介绍与示…

玩转Flume+Kafka原来也就那点事儿
好久没有写分享了,继前一个系列进行了Kafka源码分享之后,接下来进行Flume源码分析系列,望大家继续关注,今天先进行开篇文章Flumekafka的环境配置与使用。 一、FLUME介绍 Flume是一个分布式、可靠、和 高可用 的海量日志聚合的系统…

Kafka与FlumeNG整合
1,作为Producer的Flume端配置,其中是以netcat为source数据源,sink是kafka [html] view plaincopyhadoopstormspark:~/bigdata/apache-flume-1.4.0-bin$ cat conf/producer1.properties #agent section producer.sources s producer.c…

聊聊Flume和Logstash的那些事儿
在某个Logstash的场景下,我产生了为什么不能用Flume代替Logstash的疑问,因此查阅了不少材料在这里总结,大部分都是前人的工作经验下,加了一些我自己的思考在里面,希望对大家有帮助。 本文适合有一定大数据基础的读者朋…

scribe、chukwa、kafka、flume日志系统对比
1. 背景介绍许多公司的平台每天会产生大量的日志(一般为流式数据,如,搜索引擎的pv,查询等),处理这些日志需要特定的日志系统,一般而言,这些系统需要具有以下特征:&#x…
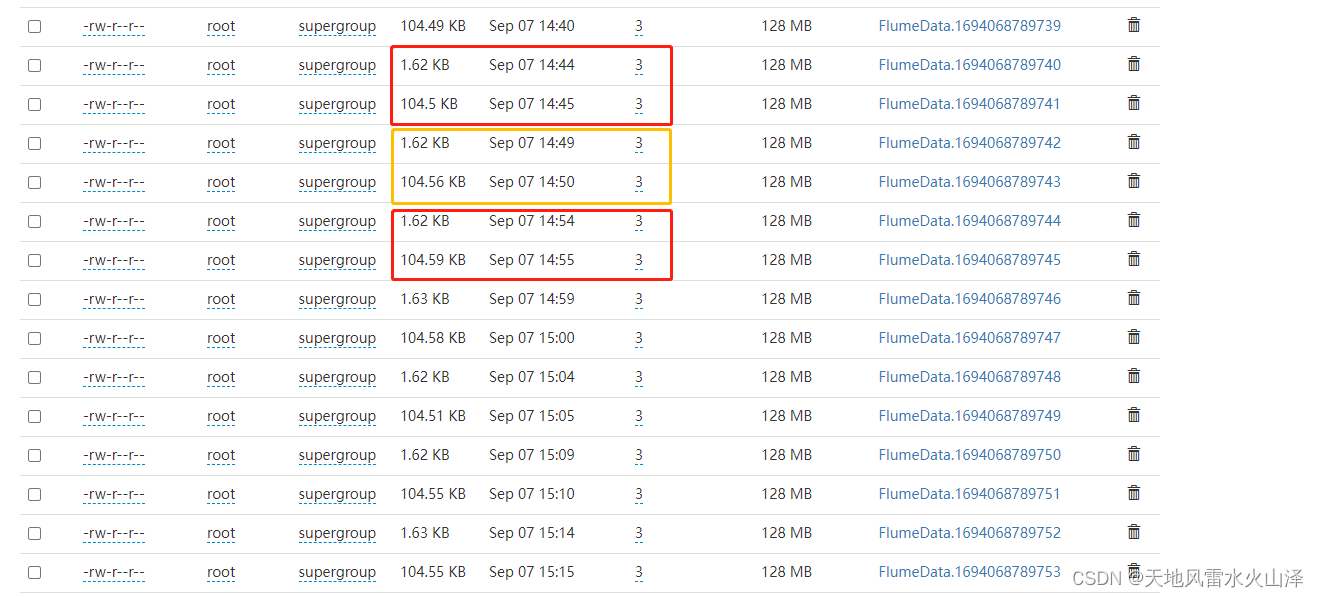
一百七十三、Flume——Flume写入HDFS后的诸多小文件问题
一、目的
在用Flume采集Kafka中的数据写入HDFS后,发现写入HDFS的不是每天一个文件,而是一个文件夹,里面有很多小文件,浪费namenode的宝贵资源 二、Flume的配置文件优化(参考了其他博文)
(一&a…

如何利用flume进行日志采集
介绍 Apache Flume 是一个分布式、可靠、高可用的日志收集、聚合和传输系统。它常用于将大量日志数据从不同的源(如Web服务器、应用程序、传感器等)收集到中心化的存储或数据处理系统中。 基本概念
Agent(代理): …

【Flume】介绍,架构,安装
目录 介绍
架构
Agent
Source
Sink
Channel
Event(事件)
安装 介绍 Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传 输的系统。Flume 基于流式架构,灵活简单。 Flume最主要的作…
离线数仓中的同步策略、Flume、Kafka
离线数仓当中Sqoop采集MySQL中数据同步策略有:增量全量新增及变化特殊;Sqoop怎么处理? where判断日期:新增:where 创建时间 当天;全量:where 1 1;新增及变化:创建时间 …
Centos7下Flume使用
Flume(日志收集系统)
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提…

【数据采集与预处理】流数据采集工具Flume
一、Flume简介
数据流 :数据流通常被视为一个随时间延续而无限增长的动态数据集合,是一组顺序、大量、快速、连续到达的数据序列。通过对流数据处理,可以进行卫星云图监测、股市走向分析、网络攻击判断、传感器实时信号分析。
(…

“上海设计100+”和“设享奖EDW”先后揭晓,深兰科技皆获大奖
国庆前夕,“上海设计100”和“设享奖EDW”两项产品设计大奖的获奖榜单先后揭晓,深兰科技出品的计算机视觉工业检测标准化设备-剑齿虎在两项大奖的评选中皆获大奖。
01上海设计100——2023世界设计之都大会 9月26日,由上海市人民政府主办&…
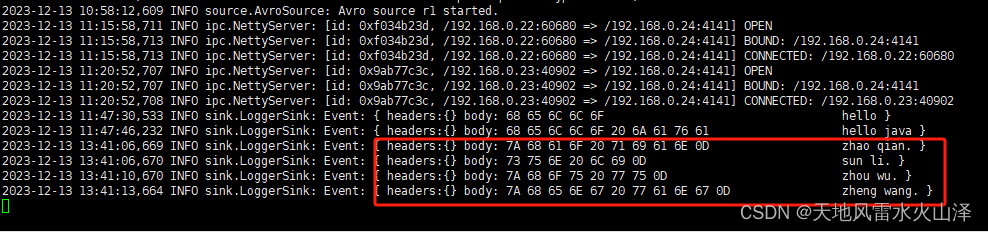
(二十一)大数据实战——Flume数据采集之复制和多路复用案例实战
前言
本节内容我们完成Flume数据采集的一个多路复用案例,使用三台服务器,一台服务器负责采集本地日志数据,通过使用Replicating ChannelSelector选择器,将采集到的数据分发到另外俩台服务器,一台服务器将数据存储到hd…
Flume多进程传输
1.Flume介绍
Flume 是一种分布式、可靠且可用的服务,用于高效收集、聚合和移动大量日志数据。它具有基于流数据流的简单而灵活的架构。它具有鲁棒性和容错性,具有可调的可靠性机制和许多故障转移和恢复机制。它使用简单的可扩展数据模型,允许…

Flume:概述、安装部署、常用Source/Sink/Channel属性、案例
目录
1、Flume概述
1.1、Flume是什么
1.2、Flume基本架构
1.2.1 Agent
1.2.2 Source
1.2.3 Channel
1.2.4 Sink
1.2.5 Event
1.3、Flume优点
1.4、Flume常用模型
2、Flume的安装部署
3、Flume常用属性配置
3.1、Source
3.1.1、Avro Source
3.1.2、Exec Source
…
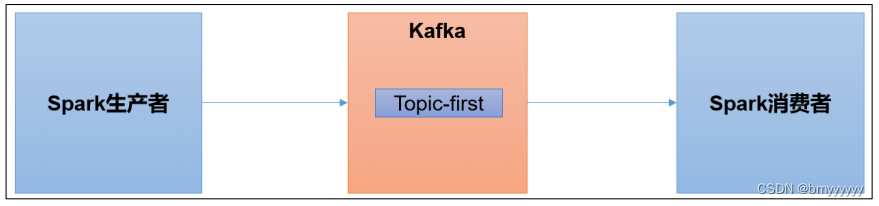
2023_Spark_实验三十:测试Flume到Kafka
实验目的:测试Flume采集数据发送到Kafka
实验方法:通过centos7集群测试,将flume采集的数据放到kafka中
实验步骤: 一、 kafka可视化工具介绍
Kafka Tool是一个用于管理和使用Apache Kafka集群的GUI应用程序。 Kafka Tool提供了…

数仓项目6.0配置大全(hadoop/Flume/zk/kafka/mysql配置)
配置背景
我使用的root用户,懒得加sudo
所有文件夹在/opt/module
所有安装包在/opt/software
所有脚本文件在/root/bin
三台虚拟机:hadoop102-103-104
分发脚本 fenfa,放在~/bin下,chmod 777 fenfa给权限
#!/bin/bash
#1. 判断参数个数…
Flume:HDFS Sink频繁生成小文件,不按照设定属性滚动文件解决方案(源码)、hdfs.minBlockReplicas作用
比如我们想要通过Flume将数据输出到HDFS中,并且希望每个文件100K左右,可以这么设置sink属性
a1.channels c1
a1.sinks k1a1.sinks.k1.type hdfs
a1.sinks.k1.channel c1
#目录名为/flume/小时-分钟/秒
a1.sinks.k1.hdfs.path /flume/%H-%M/%S
a1.s…
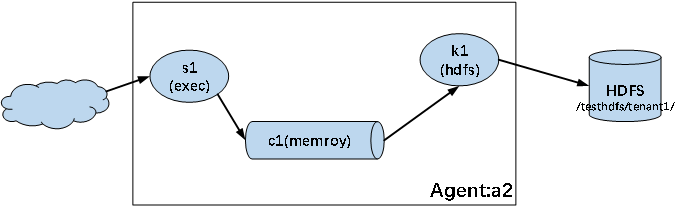
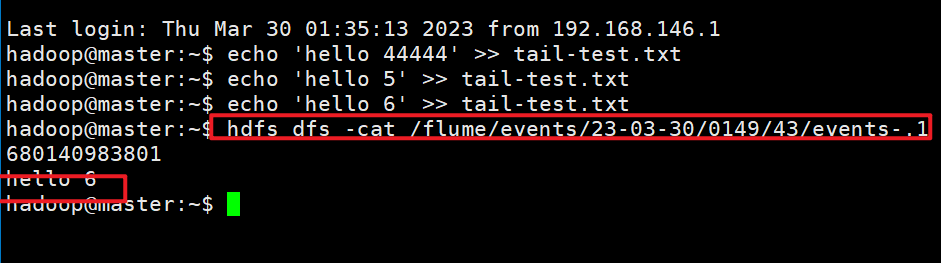
Flume实战:实时读取本地文件到HDFS
1.创建flume-hdfs.conf文件 命令:
cd /opt/module/flume-1.8.0/jobconftouch flume-hdfs.confvi flume-hdfs.conf添加内容:
# 1 agent
a2.sources r2
a2.sinks k2
a2.channels c2# 2 source
a2.sources.r2.type exec
a2.sources.r2.command tail …
flume对接kafka测试
Flume对接Kafka测试
配置文件
# example.conf: A single-node Flume configuration# Name the components on this agent
a1.sources r1
a1.sinks k1
a1.channels c1# Describe/configure the source
a1.sources.r1.type netcat
a1.sources.r1.bind localhost
a1.source…
Flume系列:案例-Flume 聚合拓扑(常见的日志收集结构)
目录
Apache Hadoop生态-目录汇总-持续更新 1:案例需求-实现聚合拓扑结构
3:实现步骤:
2.1:实现flume1.conf - sink端口4141
2.2:实现flume2.conf- sink端口4141
2.3:实现flume3.conf - 监听端口4141 …
一般纳税人缺少进项票,如何降低税负压力?
《梅梅谈税》专注于企业税务筹划!助力企业合理、合规、合法进行节税税收筹划!
大部分一般纳税人企业通常都存在进项和成本发票欠缺的问题,而进项发票欠缺,就会导致企业的增值税和企业所得税税负压力过大,那么如何解决…

日志采集传输框架之 Flume,将监听端口数据发送至Kafka
1、简介 Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传 输的系统。Flume 基于流式架构,主要有以下几个部分组成。 主要组件介绍:
1)、Flume Agent 是一个 JVM 进程…
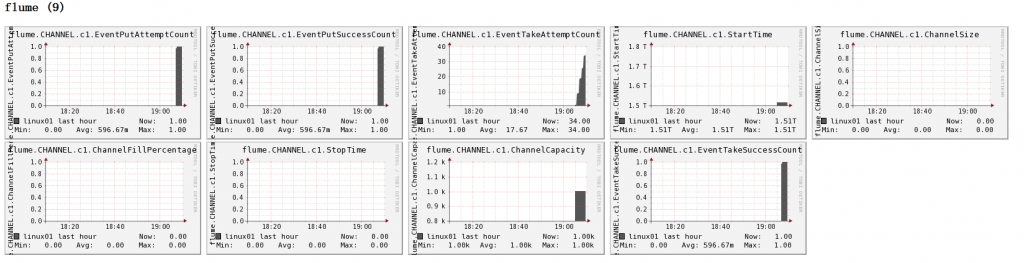
大数据培训技术操作Flume测试监控
大数据培训技术操作Flume测试监控
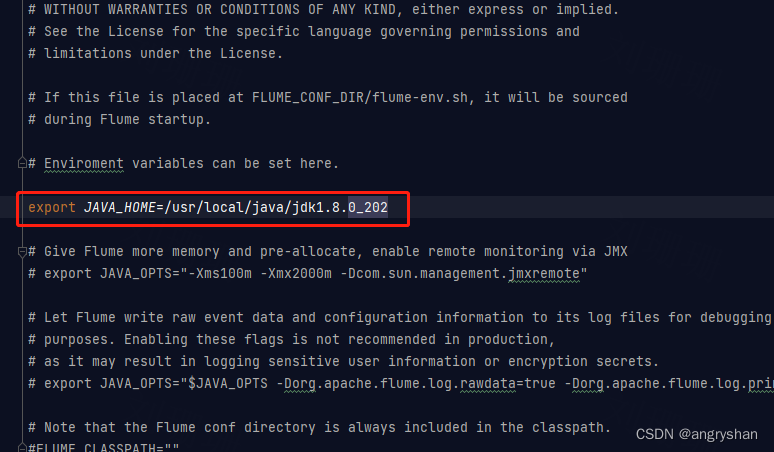
1)修改/opt/module/flume/conf目录下的flume-env.sh配置:
JAVA_OPTS”-Dflume.monitoring.typeganglia
-Dflume.monitoring.hosts192.168.9.102:8649
-Xms100m
-Xmx200m”
2)启动Flume任务
[atguiguh…

Flume 之自定义Sink
1、简介 前文我们介绍了 Flume 如何自定义 Source, 并进行案例演示,本文将接着前文,自定义Sink,在这篇文章中,将使用自定义 Source 和 自定义的 Sink 实现数据传输,让大家快速掌握Flume这门技术。
2、自定…
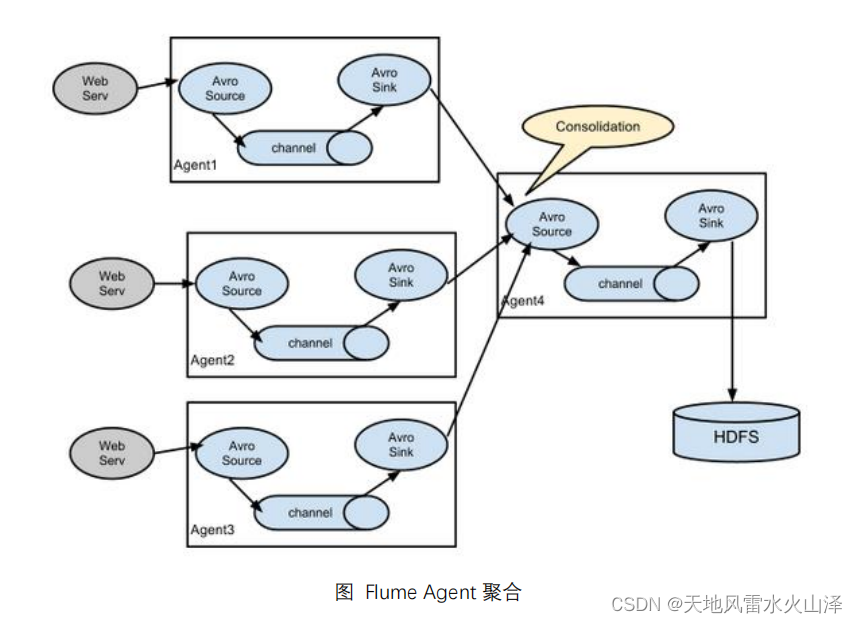
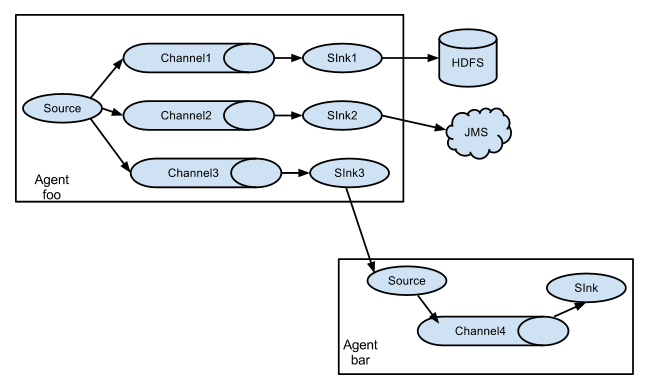
二百一十三、Flume——Flume拓扑结构介绍
一、目的
最近在看尚硅谷的Flume资料,看到拓扑结构这一块,觉得蛮有意思,于是整理一下Flume的4种拓扑结构
二、拓扑结构
(一)简单串联 1、结构含义
这种模式是将多个flume顺序连接起来了,从最初的sourc…
Hive+Flume+Kafka章节测试六错题总结
题目2:
EXTERNAL关键字的作用?[多选]
A、EXTERNAL关键字可以让用户创建一个外部表 B、创建外部表时,可以不加EXTERNAL关键字 C、通过EXTERNAL创建的外部表只删除元数据,不删除数据 D、不加EXTERNAL的时候,默认创建内…

Spark Streaming 读取Kafka数据源
1. Kfaka介绍 Kfaka是一种高吞吐量的分布式发布订阅消息系统,用户通过Kafaka系统可以发布大量的消息,同时也能实时订阅消费消息;Kafka 可以同时满足在线实时处理和批量离线处理。在公司的大数据生态系统中,可以把Kafka作为数据交换…
flume+kafka+sparkstreaming+hbase
文章目录爬虫代码MonitorCatcherpom.xml启动爬虫flume配置文件启动flume命令kafka相关命令Hive建立HBase关联表Spark StreamingSparkStreamTestpom.xml启动命令爬虫代码
Monitor
package ln;import java.io.File;public class Monitor extends Thread{Overridepublic void ru…
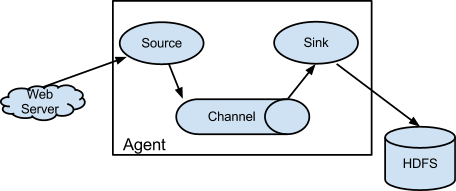
Flume三大核心组件
Flume的三大核心组件: Source:数据源 Channel:临时存储数据的管道 Sink:目的地 Source:数据源:通过source组件可以指定让Flume读取哪里的数据,然后将数据传递给后面的 channel
Flume内置支持读…
Flume 入门教程(超详细)
文章目录1. Flume 概述1.1 Flume 定义1.2 Flume 基础架构1.2.1 Agent1.2.2 Source1.2.3 Sink1.2.4 Channel1.2.5 Event2. Flume 的安装2.1 安装地址2.2 安装流程3. Flume 入门案例3.1 监控端口数据3.1.1 需求3.1.2 分析3.1.3 实现流程3.2 监控单个追加文件3.2.1 需求3.2.2 分析…
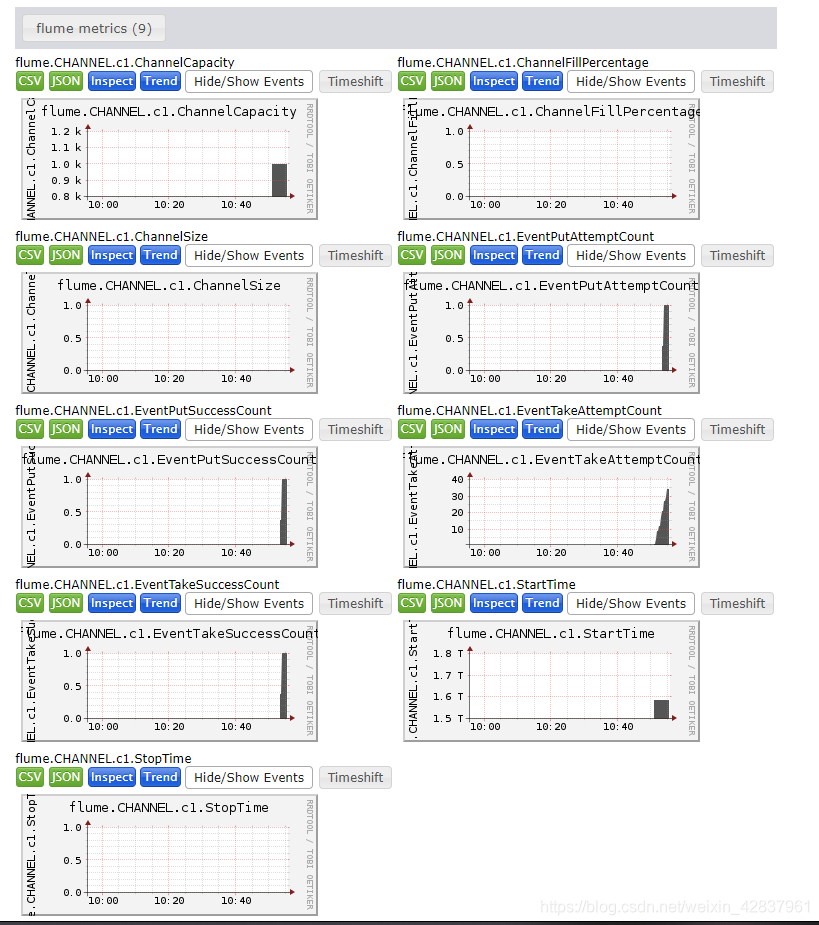
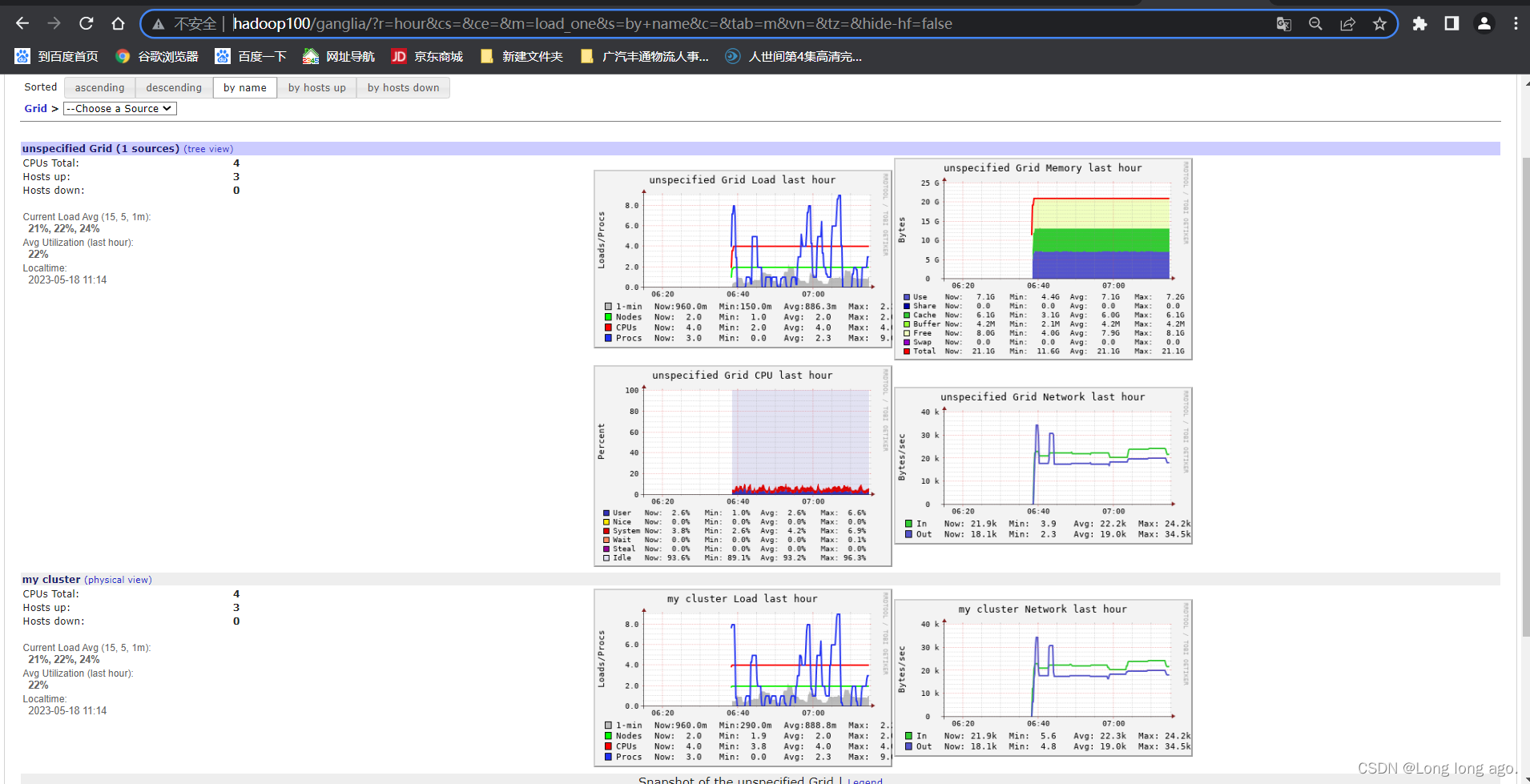
(二十四)大数据实战——Flume数据流监控之Ganglia的安装与部署
前言
本节内容我们主要介绍一下Flume数据流的监控工具Ganglia。Ganglia是一个开源的分布式系统性能监控工具。它被设计用于监视大规模的计算机群集(包括集群、网格和云环境),以便收集和展示系统和应用程序的性能数据。Ganglia 可以轻松地扩展…
flume安装使用指南
flume安装使用 安装
tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /opt/
cd /opt/
mv apache-flume-1.9.0-bin flume
cd /opt/flume/conf
vim log4j.properties更改日志目录
flume.log.dir/opt/flume/logs运行测试
touch /opt/flume/conf/example.conf
vim /opt/flume/conf/…

尚硅谷Flume(仅有基础)
q
1 概述
1.1 定义 Flume 是Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume 基于流式架构,灵活简单。 Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HD…
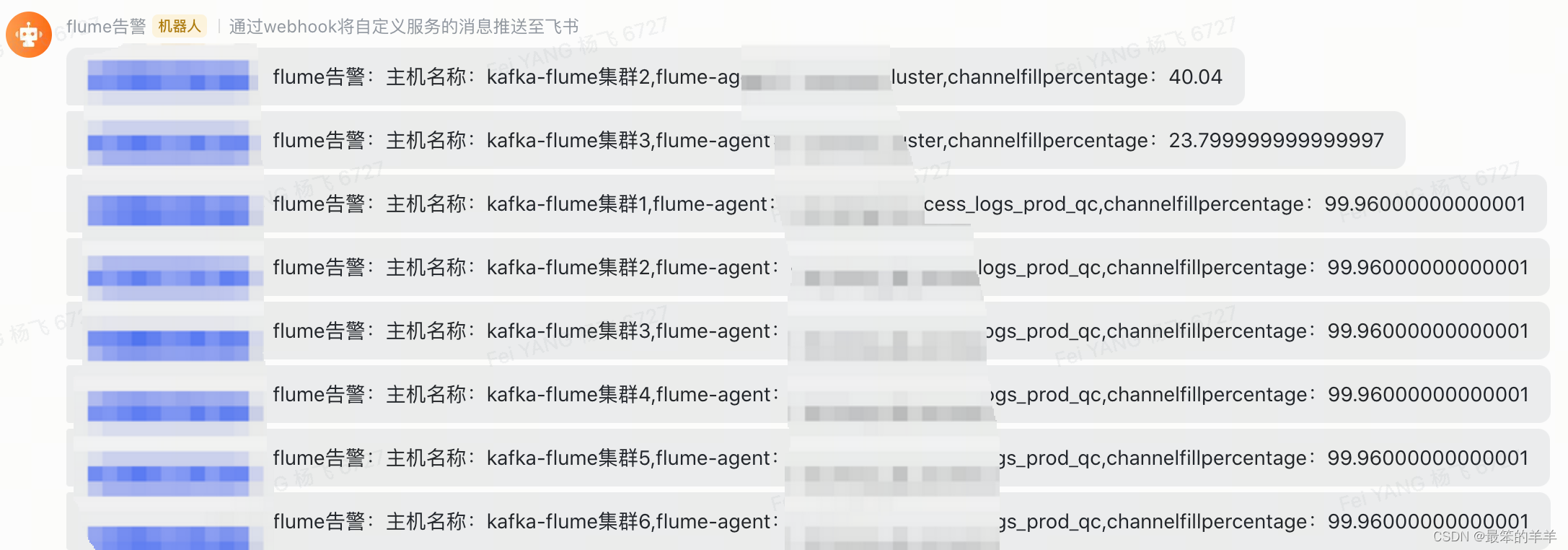
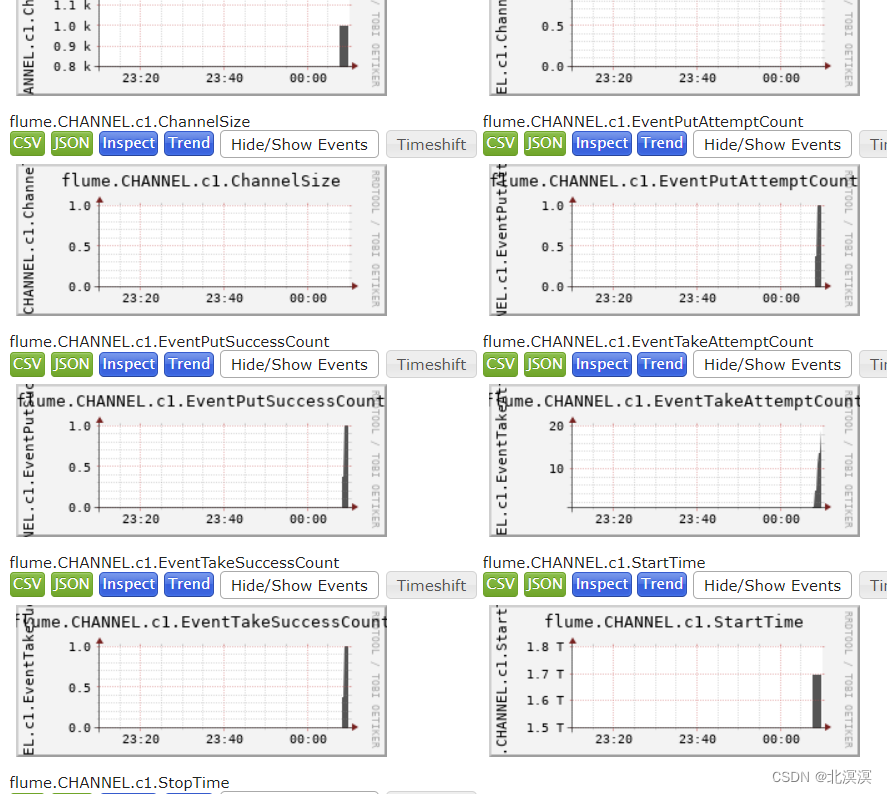
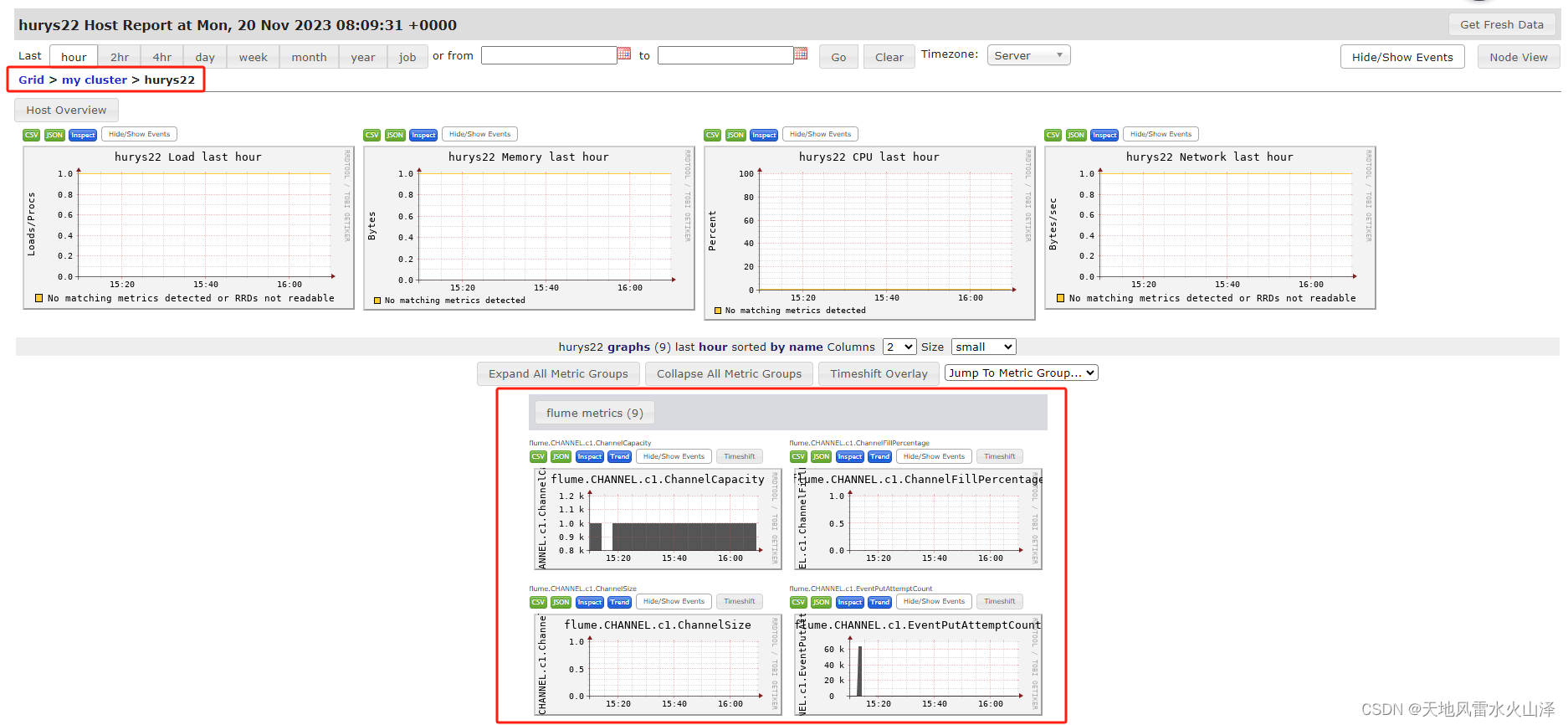
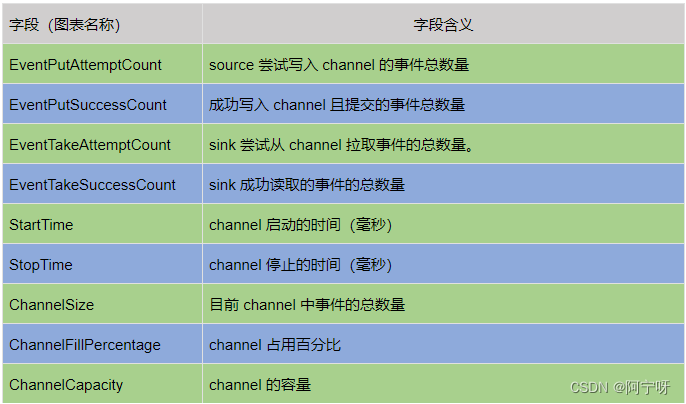
flume系列之:监控flume agent channel的填充百分比
flume系列之:监控flume agent channel的填充百分比 一、监控效果二、获取flume agent三、飞书告警四、获取每个flume agent channel的填充百分比一、监控效果 二、获取flume agent def getKafkaFlumeAgent():# 腾讯云10.130.112.60zk = KazooClient(hosts
有赞统一日志平台初探
【编者的话】从2015年初入职有赞以来,一直致力于后端服务开发,主要设计开发了监控系统Hawk,但这不是本次要分享的点。一个月前,负责日志平台Track的小伙伴寻求梦想出去创业了,有幸接手了日志平台,这对本人确…
TikTok美区本土店铺如何做好IP隔离?
为什么要进行IP隔离呢?因为我们无法在国内直接运营Shopee、TikTok、Lazada等平台的本土店,平台识别出店铺登录IP非本土IP,则容易导致店铺风控、被标记为伪本土店,影响店铺经营。
TikTok美区店铺的IP隔离方法和Shopee本土店一致&a…

问道管理:机器人概念走势活跃,新时达涨停,拓斯达、丰立智能等大涨
机器人概念17日盘中走势活跃,到发稿,拓斯达大涨18%,昊志机电涨近16%,丰立智能涨超13%,步科股份、优德精细涨超10%,新时达涨停,天玑科技、兆龙互联、中大力德涨逾9%。 消息面上,8月16…
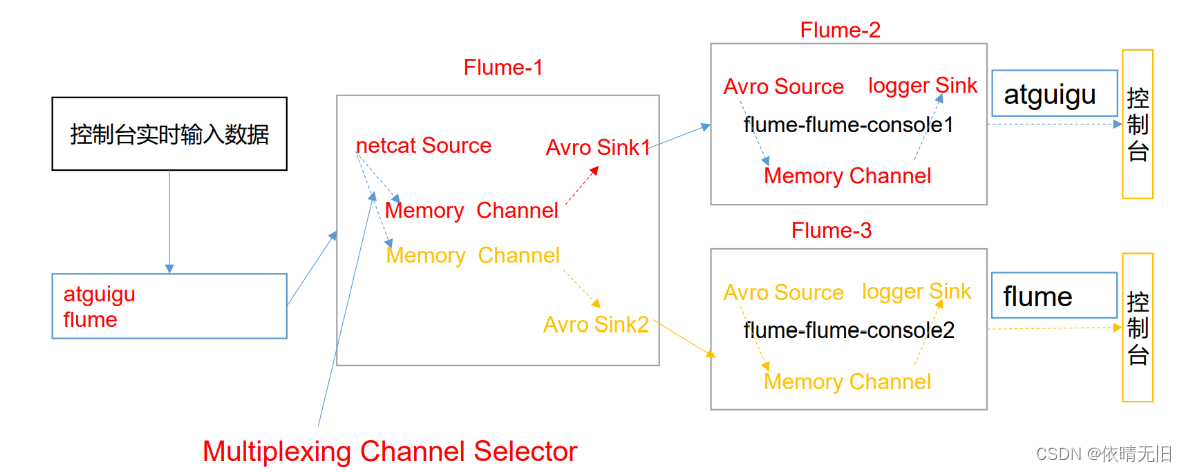
Flume基础知识(十一):Flume自定义接口
1)案例需求 使用 Flume 采集服务器本地日志,需要按照日志类型的不同,将不同种类的日志发往不同的分析系统。 2)需求分析 在实际的开发中,一台服务器产生的日志类型可能有很多种,不同类型的日志可能需要 发送…
Spark Streaming与数据源连接:Kinesis、Flume等
在大数据领域,实时数据处理变得越来越重要。Apache Spark Streaming是一个强大的工具,可用于处理实时数据流。本文将介绍如何使用Spark Streaming连接各种数据源,包括Amazon Kinesis、Apache Flume等,并提供详细的示例代码&#x…
Flume基础知识(四):Flume实战之实时监控单个追加文件
1)案例需求: 实时监控 Hive 日志,并上传到 HDFS 中 2)需求分析: 3)实现步骤: (1)Flume 要想将数据输出到 HDFS,依赖 Hadoop 相关 jar 包
检查/etc/profile.d…
Flume采集Kafka并把数据sink到OSS
安装环境
Java环境, 略 (Flume依赖Java)Flume下载, 略Scala环境, 略 (Kafka依赖Scala)Kafak下载, 略Hadoop下载, 略 (不需要启动, 写OSS依赖)
配置Hadoop
下载JindoSDK(连接OSS依赖), 下载地址Github 解压后配置环境变量
export JINDOSDK_HOME/usr/lib/jindosdk-x.x.x
expo…
Flume 快速入门【概述、安装、拦截器】
文章目录 什么是 Flume?Flume 组成Flume 安装Flume 配置任务文件应用示例启动 Flume 采集任务 Flume 拦截器编写 Flume 拦截器拦截器应用 什么是 Flume?
Flume 是一个开源的数据采集工具,最初由 Apache 软件基金会开发和维护。它的主要目的是…
Flume 入门--几种不同的Sinks
主要介绍几种常见Flume的Sink--汇聚点1.Logger Sink 记录INFO级别的日志,一般用于调试。前面介绍Source时候用到的Sink都是这个类型的Sink必须配置的属性:属性说明: !channel – !type – The component…
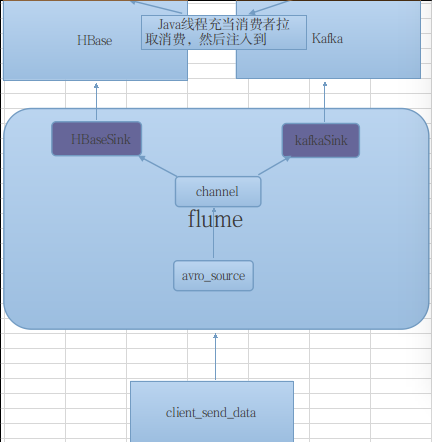
flume安装及配置介绍(二)
注: 环境: skylin-linuxFlume的下载方式: wget http://www.apache.org/dyn/closer.lua/flume/1.6.0/apache-flume-1.6.0-bin.tar.下载完成之后,使用tar进行解压tar -zvxf apache-flume-1.6..0-bin.tar.进入flume的conf配置包…
增值税税负高?设备贸易企业这样做可节税高达40%?
《梅梅谈税》专注于企业税务筹划!助力企业合理、合规、合法进行节税税收筹划!
机械设备是我们日常生活中不可或缺的商品,各行各业都要用到,例如大型医疗设备,汽车制造设备、芯片制造、机床等等, 机械贸易企…

Flume(NG)架构设计要点及配置实践
Flume NG是一个分布式、可靠、可用的系统,它能够将不同数据源的海量日志数据进行高效收集、聚合、移动,最后存储到一个中心化数据存储系统中。由原来的Flume OG到现在的Flume NG,进行了架构重构,并且现在NG版本完全不兼容原来的OG…
flume学习:自定义拦截器
回想一下,spooldir source可以将文件名作为header中的key:basename写入到event的header当中去。试想一下,如果有一个拦截器可以拦截这个event,然后抽取header中这个key的值,将其拆分成3段,每一段都放入到header中,这样…
基于Flume的美团日志收集系统(二)改进和优化
在《基于Flume的美团日志收集系统(一)架构和设计》中,我们详述了基于Flume的美团日志收集系统的架构设计,以及为什么做这样的设计。在本节中,我们将会讲述在实际部署和使用过程中遇到的问题,对Flume的功能改进和对系统做的优化。 …
消费flume的数据无法上传到HDFS
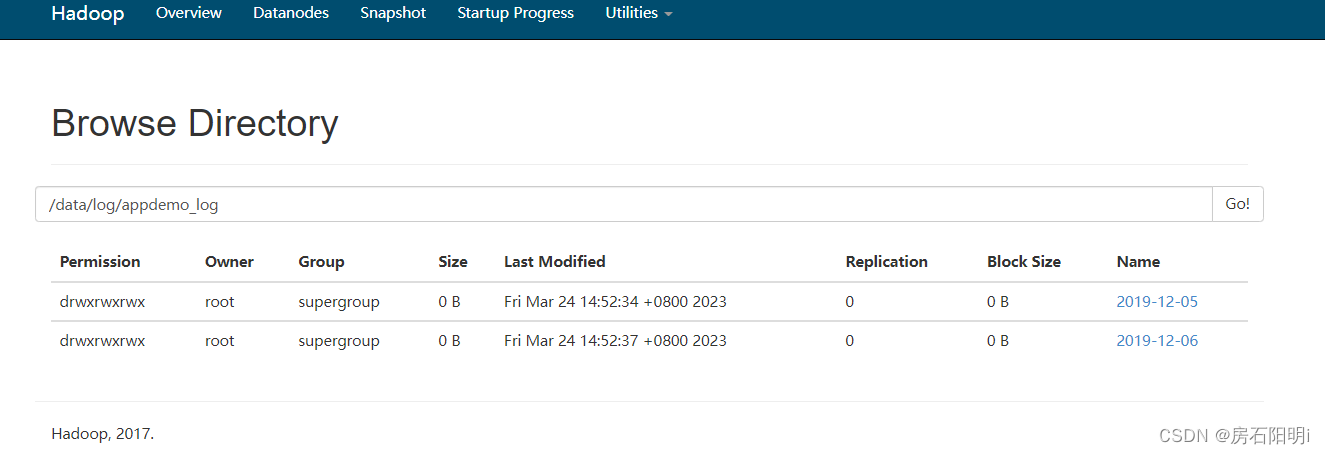
问题:打开hadoop102:9870发现没有出现flume的数据
检查采集flume这部分,在kafka里可以读取到数据,说明是消费flume这部分出错,检查日志信息。
使用消费flume启动停止脚本,可以看到日志信息是在 /opt/module/flume/lo…
大数据技术之flume——日志收集系统
一、flume概述1.1 flume定义大数据需要解决的三个问题:采集、存储、计算。Apache flume是一个分布式、可靠的、高可用的海量日志数据采集、聚合和传输系统,将海量的日志数据从不同的数据源移动到一个中央的存储系统中。用一句话总结:Flume不生…
Hdoop学习笔记(HDP)-Part.20 安装Flume
目录 Part.01 关于HDP Part.02 核心组件原理 Part.03 资源规划 Part.04 基础环境配置 Part.05 Yum源配置 Part.06 安装OracleJDK Part.07 安装MySQL Part.08 部署Ambari集群 Part.09 安装OpenLDAP Part.10 创建集群 Part.11 安装Kerberos Part.12 安装HDFS Part.13 安装Ranger …

flume安装部署及使用
文章目录前言一、Flume定义二、Flume安装部署1.上传压缩包2.解压、修改配置文件2.1解压2.2修改配置文件三、Flume简单使用3.1 使用 Flume 监听一个端口,收集该端口数据,并打印到控制台3.2 使用 Flume 监听本地目录,将目录下的文件上传hdfs前言…

Flume 开发 (企业开发案例)
1.监控端口数据案例
1)案例需求 首先启动Flume任务,监控本机44444端口 [服务端]; 然后通过netcat工具向本机44444端口发送消息 [客户端]; 最后Flume将监听的数据实时显示在控制台。 2)需求分析 3)实现步骤
1
[rootflume0 apache-flume-1.…
flume采集文件写hdfs不能创建目录的问题
用exec source运行flume-ng agent后hdfs上不能创建指定的文件目录,可能的三种情况如下
一、配置文件中的监听端口和hadoop下的core-site.xml中的端口不一致
在我新建的.conf文件里面,需要配置hdfs的路径
hdfs://192.168.122.102:9000/flume/upload/%Y…
java大数据hadoop2.9.2 Flume安装操作
1、flume安装
(1)解压缩
tar -xzvf apache-flume-1.9.0-bin.tar.gz
rm -rf apache-flume-1.9.0-bin.tar.gz
mv ./apache-flume-1.9.0-bin/ /usr/local/flume
(2)配置
cd /usr/local/flume/conf
cp ./flume-env.sh.template…
nginx日志切割并使用flume-ng收集日志
nginx的日志文件没有rotate功能。如果你不处理,日志文件将变得越来越大,还好我们可以写一个nginx日志切割脚本来自动切割日志文件。第一步就是重命名日志文件,不用担心重命名后nginx找不到日志文件而丢失日志。在你未重新打开原名字的日志文件…
大数据基础设施搭建 - Flume
文章目录 一、上传压缩包二、解压压缩包三、监控本地文件(file to kafka)3.1 编写配置文件3.2 自定义拦截器3.2.1 开发拦截器jar包(1)创建maven项目(2)开发拦截器类(3)开发pom文件&a…
大数据日志收集框架之Flume入门
Flume是Cloudrea公司开源的一款优秀的日志收集框架,主要经历了两个大的版本,分别是 Flume-OG Flume-NG OG是0.9.x的版本,依赖zookeeper,角色职责不够单一, NG是新版本指1.x的版本,官网解释它更轻量级&a…
Attempt to do update or delete using transaction manager
Hive报错:Attempt to do update or delete using transaction manager报错原因默认在hive中没有默认开启支持单条插入(update)、更新以及删除(delete)操作,需要自己配置。而在默认情况下,当用户…
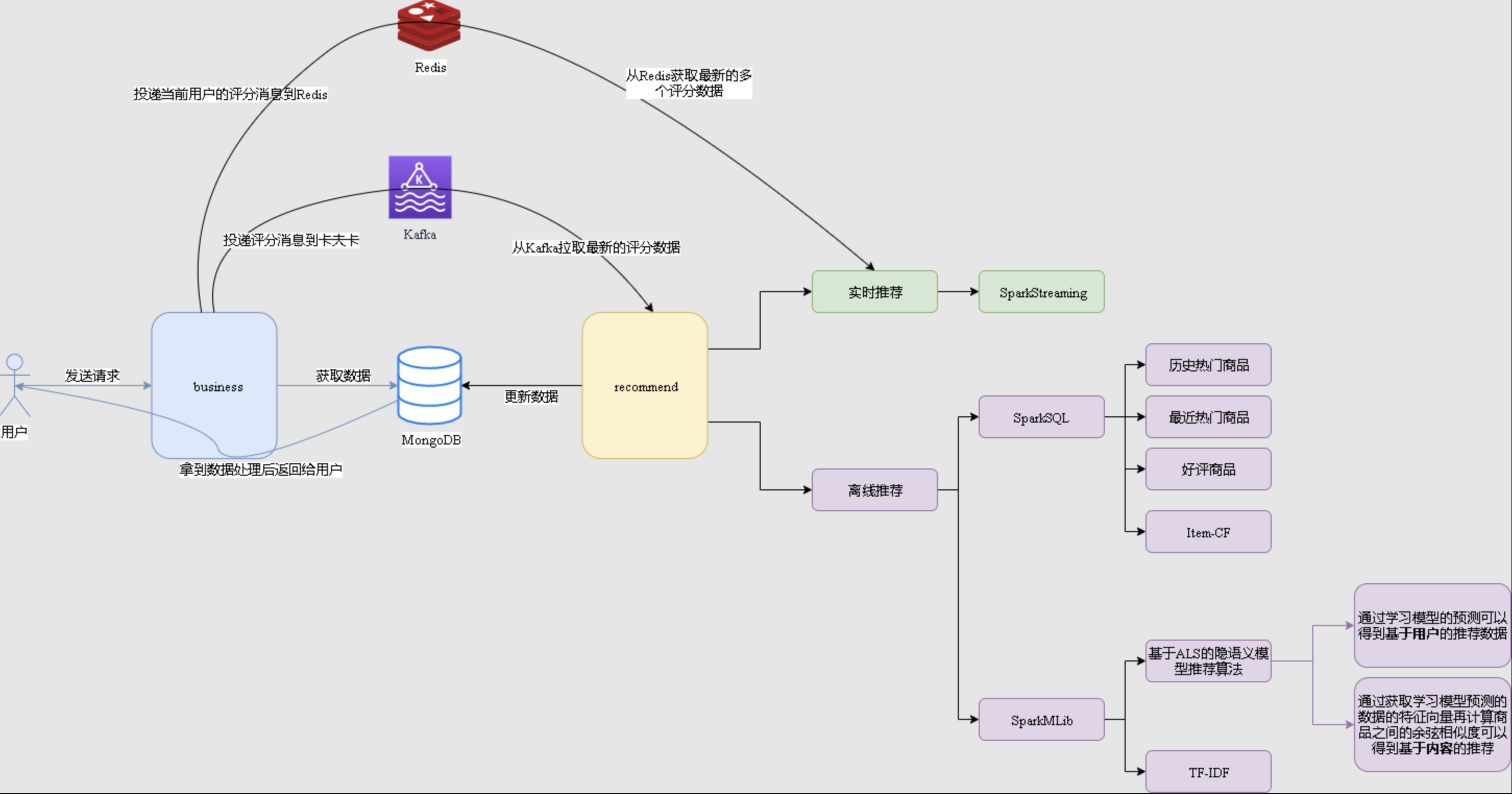
大数据实战项目_电商推荐系统
一、 项目介绍
HadoopSpark (Python)Scala SparkSQLSparkStreaming MongoDB Redis Kafka Flume ( SpringMVC vue)
1 项目介绍
1.1 项目系统架构
项目以推荐系统建设领域知名的经过修改过的中文亚马逊电商数据集作为依托,以某电商网站真实业务数据架构为基…
大数据组件-Flume集群环境搭建
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇 个人主页:beixi 本文章收录于专栏(点击传送):【大数据学习】 💓💓持续更新中,感谢各位前辈朋友们支持…
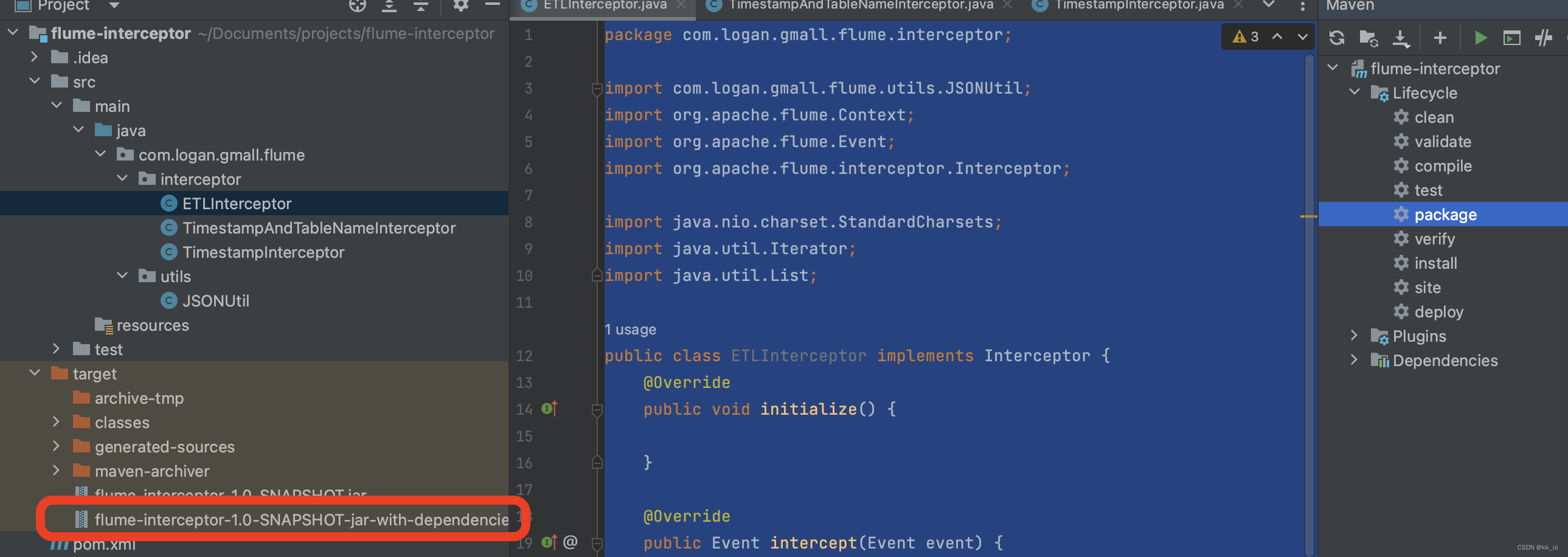
大数据项目之电商数仓、日志采集Flume配置概述、日志采集Flume配置实操
文章目录4. 用户行为数据采集模块4.3 日志采集Flume4.3.2 日志采集Flume配置概述4.3.2.1 TailDirSource4.3.2.2 KafkaChannel4.3.3 日志采集Flume配置实操4.3.3.1 创建Flume配置文件4.3.3.2 配置文件内容如下4.3.3.3 编写Flume拦截器4.3.3.3.1 创建Maven工程flume-interceptor4…

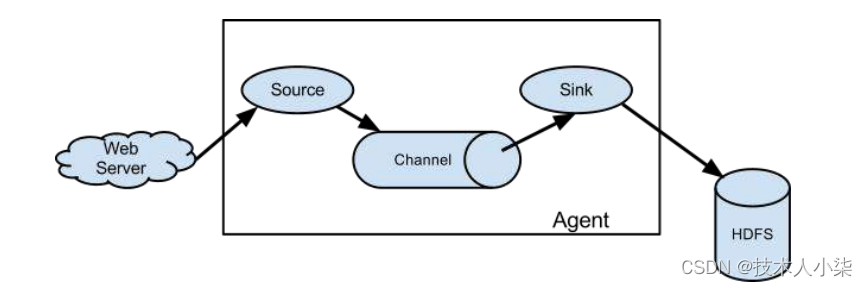
Flume(1)—— 配置和官方最简案例(NetCat Source、Logger Sink)
Flume(1)——配置和官方最简案例(NetCat Source、Logger Sink)官方网址http://flume.apache.org/FlumeUserGuide.htmlFlume组成部分Flume的主要组成部分就是Agent和Agent中的Source、Channel、Sink。Source、Channel、Sink都有固定…
大数据开发必备面试题Flume篇合集
大数据开发必备面试题Flume篇合集 1 、详细介绍Flume有哪些组件?2、你是如何实现Flume数据传输的监控的?3、Flume参数怎么调优?4、简述下Flume的事务机制。5、 Flume采集数据会丢失吗?6、简述下Flume使用场景。7、简述下 Flume丢包问题。8、…
linux安装配置 flume
目录
一 解压安装包
二 配置部署 (1)修改配置 (2)下载工具 (3)创建配置文件 (4)启动监听测试 (5)flume监控文件 一 解压安装包 这里提供了网盘资源
链…
级联flume报错 输出方无法连接接收方
今天犯了一个低级的错误,在排查过程中学到一些知识,特此记录,加深印象。
需求
模拟后台业务日志采集程序,多个服务器不停地生成多种日志内容,我需要在每台机器上启动输出方flume,然后把输出方flume的数据…
flume的配置与安装
一.flume的配置与案例1 下载flume包
http://mirrors.tuna.tsinghua.edu.cn/apache/flume/1.8.0/apache-flume-1.8.0-bin.tar.gz1.将压缩包放在ubunta下
cd ~
tar -zxvf apache-flume-1.8.0-bin.tar.gz -C ~ln -s apache-flume-1.8.0-bin/ flumevi ~/.bashrc
source ~/.bashrc…
二百一十六、Flume——Flume拓扑结构之负载均衡和故障转移的开发案例(亲测,附截图)
一、目的
对于Flume的负载均衡和故障转移拓扑结构,进行一个开发测试
二、负载均衡和故障转移 (一)结构含义
Flume支持使用将多个sink逻辑上分到一个sink组
(二)结构特征
sink组配合不同的SinkProcessor可以实现负…
sqoop和flume简单安装配置使用
1. Sqoop
1.1 Sqoop介绍 Sqoop 是一个在结构化数据和 Hadoop 之间进行批量数据迁移的工具 结构化数据可以是MySQL、Oracle等关系型数据库 把关系型数据库的数据导入到 Hadoop 与其相关的系统 把数据从 Hadoop 系统里抽取并导出到关系型数据库里 底层用 MapReduce 实现数据 …
二百零七、Flume——Flume实时采集5分钟频率的Kafka数据直接写入ODS层表的HDFS文件路径下
一、目的
在离线数仓中,需要用Flume去采集Kafka中的数据,然后写入HDFS中。
由于每种数据类型的频率、数据大小、数据规模不同,因此每种数据的采集需要不同的Flume配置文件。玩了几天Flume,感觉Flume的使用难点就是配置文件
二、…
Linux下安装Flume
1 下载Flume
Welcome to Apache Flume — Apache Flume
下载1.9.0版本
2 上传服务器并解压安装
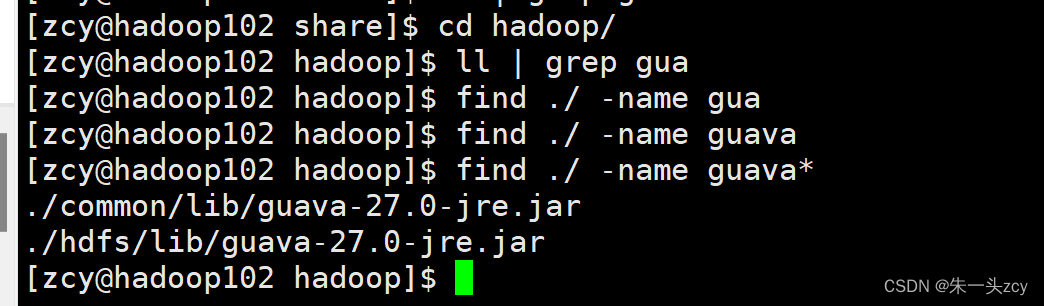
3 删除lib目录下的guava-11.0.2.jar (如同服务器安装了hadoop,则删除,如没有安装hadoop则保留这个文件,否则无法启动flume&#…

Flume学习笔记(1)—— Flume入门
Flume 概述
Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统
Flume 基于流式架构,灵活简单
Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS
基础架…
记录一下互联网日志实时收集和实时计算的简单方案
作为互联网公司,网站监测日志当然是数据的最大来源。我们目前的规模也不大,每天的日志量大约1TB。后续90%以上的业务都是需要基于日志来完成,之前,业务中对实时的要求并不高,最多也就是准实时(延迟半小时以…
Apache Flume架构和原理
Apache Flume是一个开源的分布式、可靠的日志收集和聚合系统,旨在将大量的日志数据从不同的数据源(如应用程序、服务器、设备)收集到中心存储或数据湖中。Flume的架构设计允许用户在大规模数据流的情况下实现可靠的数据传输和处理。
Flume特性
Apache Flume是一个用于收集…
2024.2.10 HCIA - Big Data笔记
1. 大数据发展趋势与鲲鹏大数据大数据时代大数据的应用领域企业所面临的挑战和机遇华为鲲鹏解决方案2. HDFS分布式文件系统和ZooKeeperHDFS分布式文件系统HDFS概述HDFS相关概念HDFS体系架构HDFS关键特性HDFS数据读写流程ZooKeeper分布式协调服务ZooKeeper概述ZooKeeper体系结构…

第二证券:汇金增持有望催化银行板块 白酒企稳信号凸显
昨日,两市股指盘中震动上扬,创业板指、科创50指数一度涨超1%,但沪指午后涨幅逐渐回落。到收盘,沪指涨0.12%报3078.96点,深成指涨0.35%报10084.89点,创业板指涨0.8%报2003.9点,科创50指数涨1.29%…

开放式耳机百元价位推荐哪款比较好一点、最值得入手的开放式耳机
不知道有没有和我一样的朋友,在工作的时候喜欢带着耳机,享受音乐带来的愉悦。然而,传统的入耳式耳机在长时间佩戴时会给耳朵带来不适感,甚至损害听力。
因此我现在会使用开放式耳机,采用了开放式设计,不需…
Hadoop生态圈中的Flume数据日志采集工具
Hadoop生态圈中的Flume数据日志采集工具 一、数据采集的问题二、数据采集一般使用的技术三、扩展:通过爬虫技术采集第三方网站数据四、Flume日志采集工具概述五、Flume采集数据的时候,核心是编写Flume的采集脚本xxx.conf六、Flume案例实操1、采集一个网络…

分布式系统监控软件Ganglia的安装和配置
1)在66服务器(主服务器)上下载安装监控软件Ganglia。
yum install -y epel-release ganglia-gmetad ganglia-devel ganglia-gmond rrdtool httpd ganglia-web php
4)在88和99服务器(非主服务器)上下载安装…
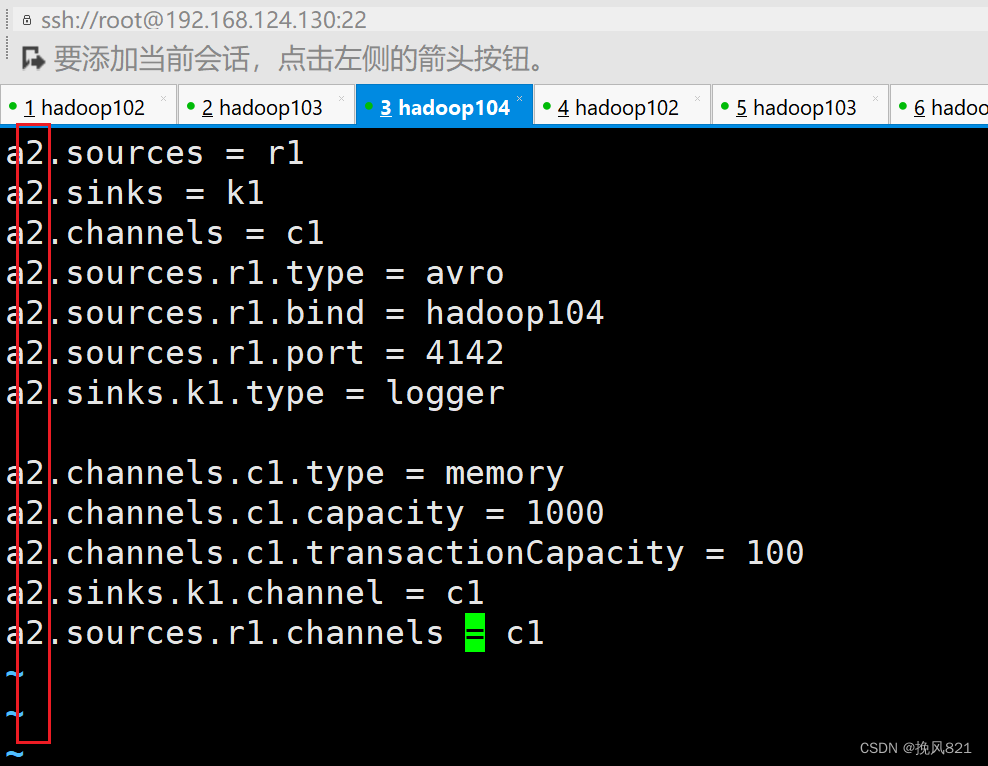
Caused by: java.net.ConnectException: 拒绝连接: hadoop104/192.168.124.130:4142
项目场景:hadoop102接收消息,自定义拦截器,包含hello的发往hadoop103,不包含的发往hadoop104
报错原因:
原因1:
应该先开启接收方(服务端),hadoop103,hadoop104,最后开启hadoop10…
Flume 安装与部署
目录 Flume 下载地址 (1)将 apache-flume-1.9.0-bin.tar.gz 上传到 linux 的 /opt/software 目录下
(2)解压 apache-flume-1.9.0-bin.tar.gz 到 /opt/module/ 目录下
huweihadoop101 ~]$ tar -zxvf /opt/software/apache-flume-…

Apache Flume(4):日志文件监控
1 案例说明
企业中应用程序部署后会将日志写入到文件中,可以使用Flume从各个日志文件将日志收集到日志中心以便于查找和分析。
2 使用Exec Soucre
Exec Source
Exec Source通过指定命令监控文件的变化,加粗属性为必须设置的。
属性名默认值说明chan…
2024-02-08(Flume)
1.Flume 的架构和MQ消息队列有点类似
2.Flume也可以做数据的持久化操作
在Channel部分选择使用File channel组件
3.Flume进行日志文件监控
场景:企业中应用程序部署后会将日志写入到文件中,我们可以使用Flume从各个日志文件将日志收集到日志中心以便…
SeaTunnel 、DataX 、Sqoop、Flume、Flink CDC 对比
对比 对比项Apache SeaTunnelDataXApache SqoopApache FlumeFlink CDC部署难度容易容易中等,依赖于 Hadoop 生态系统容易中等,依赖于 Hadoop 生态系统运行模式分布式,也支持单机单机本身不是分布式框架,依赖 Hadoop MR 实现分布式分布式,也支持单机分布式,也支持单机健壮…

大数据Flume--入门
文章目录 FlumeFlume 定义Flume 基础架构AgentSourceSinkChannelEvent Flume 安装部署安装地址安装部署 Flume 入门案例监控端口数据官方案例实时监控单个追加文件实时监控目录下多个新文件实时监控目录下的多个追加文件 Flume
Flume 定义
Flume 是 Cloudera 提供的一个高可用…

欧洲市场再获突破,挪威复购深兰科技AI清洁机器人
近日,深兰科技举办年度渠道建设大会,获得国内外市场的积极反响。值得一提的是,深兰科技国际业务部再拓市场,欧洲挪威地区经销商再次复购一批深兰科技清洁机器人产品。这是继年初深兰科技机器人产品首次成功出口挪威之后࿰…
(十九)大数据实战——Flume数据采集框架安装部署
前言
本节内容我们主要介绍一下大数据数据采集框架flume的安装部署,Flume 是一款流行的开源分布式系统,用于高效地采集、汇总和传输大规模数据。它主要用于处理大量产生的日志数据和事件流。Flume 支持从各种数据源(如日志文件、消息队列、数…

Flume 从入门到精通
Flume Flume 是一种分布式、可靠且可用的服务 高效收集、聚合和移动大量日志 数据。 它具有基于流媒体的简单灵活的架构 数据流。它坚固耐用,容错,可靠性可调 机制以及许多故障转移和恢复机制。 它 使用允许在线分析的简单可扩展数据模型 应用。 系统要求…

大数据常见面试题之Spark Streaming
文章目录一.SparkStreaming有哪几种方式消费kafka中的数据,他们之间的区别是什么?1.基于Receiver的方式2.基于Direct的方式3.两者对比二.Spark Streaming窗口函数的原理三.spark streaming 容错原理一.SparkStreaming有哪几种方式消费kafka中的数据,他们之间的区别是什么?
1…
Flume采集日志存储到HDFS
1 日志服务器上配置Flume,采集本地日志文件,发送到172.19.115.96 的flume上进行聚合,如日志服务器有多组,则在多台服务器上配置相同的配置
# Name the components on this agent
a1.sources r1
a1.sinks k1
a1.channels c1# Describe/con…
docker-compose部署flume
一、docker-compose部署
1. 依赖的服务/组件
java8flume 1.9.0
2. 下载离线安装包
jdk8https://repo.huaweicloud.com/java/jdk/8u202-b08/jdk-8u202-linux-x64.tar.gzflume 1.9.0https://mirrors.tuna.tsinghua.edu.cn/apache/flume/1.9.0/apache-flume-1.9.0-bin.tar.gzs…

浅谈安全检查“三要素” ,一看二问三检测,ECRS工时分析软件
安全检查是企业搞好安全生产常用的主要方法和手段,检查能发现问题、解决问题、预防事故的发生。如何更好、更有效地开展安全检查,达到预定的目的,个人认为,在实施检查时,“一看、二问、三检测”是检查者必须要掌握和抓…

2024-02-19(Flume,DataX)
1.flume中拦截器的作用:个人认为就是修改或者删除事件中的信息(处理一下事件)。
2.一些拦截器
Host Interceptor,Timestamp Interceptor,Static Interceptor,UUID Interceptor,Search and Rep…

深入探索Apache Flume:大数据领域的数据采集神器【上进小菜猪大数据系列】
📬📬我是上进小菜猪,沈工大软件工程专业,爱好敲代码,持续输出干货,欢迎关注。
引言: 随着大数据技术的快速发展,企业和组织需要从各种来源采集海量数据。数据采集是大数据处理流程中…
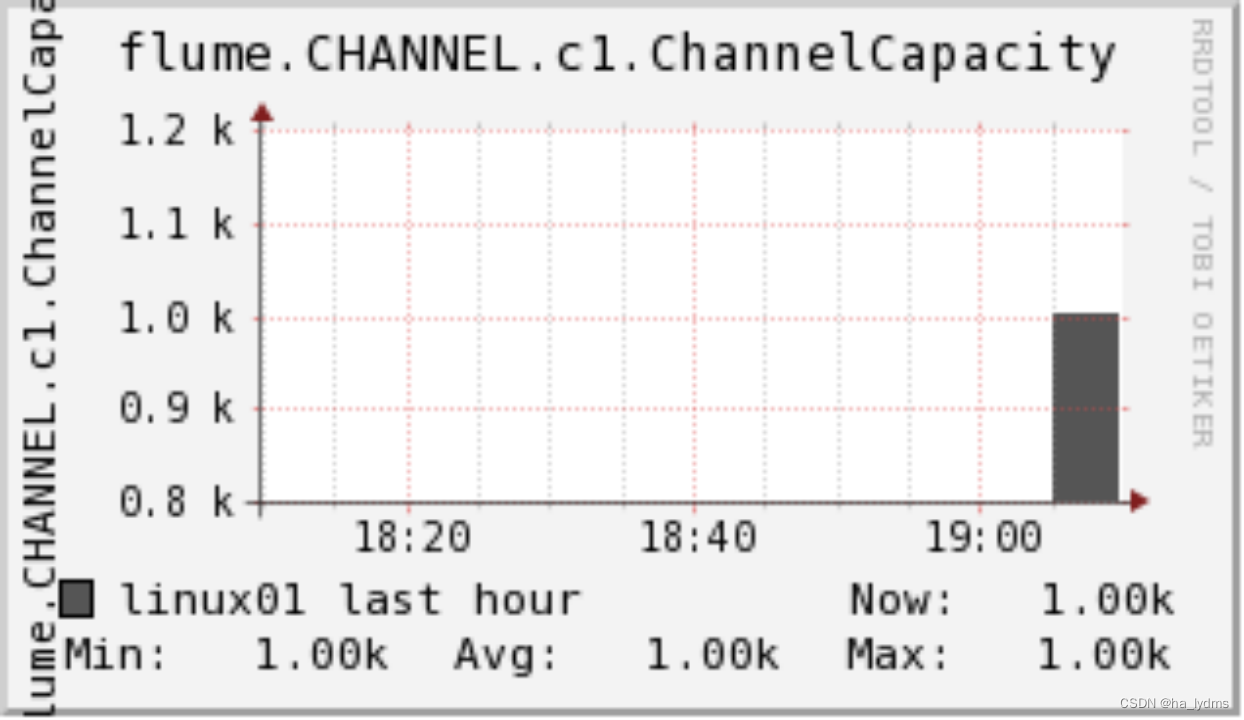
二百零五、Flume——数据流监控工具Ganglia单机版安装以及使用Ganglia监控Flume任务的数据流(附流程截图)
一、目的
Flume采集Kafka的数据流需要实时监控,这时就需要用到监控工具Ganglia
二、Ganglia简介 Ganglia 由 gmond、gmetad 和 gweb 三部分组成。 (一)第一部分:gmond gmond(Ganglia Monitoring Daemon)…

Apache Flume(3):数据持久化
1 使用组件
File Channel 2 属性设置
属性名默认值说明type-filecheckpointDir~/.flume/file-channel/checkpoint检查点文件存放路径dataDirs~/.flume/file-channel/data日志存储路径,多个路径使用逗号分隔. 使用不同的磁盘上的多个路径能提高file channel的性能 …

大数据-玩转数据-Flume
一、Flume简介 Flume提供一个分布式的,可靠的,对大数据量的日志进行高效收集、聚集、移动的服务,Flume只能在Unix环境下运行。Flume基于流式架构,容错性强,也很灵活简单。Flume、Kafka用来实时进行数据收集,Spark、Flink用来实时处理数据,impala用来实时查询。二、Flume…
二百二十五、海豚调度器——用DolphinScheduler调度执行Flume数据采集任务
一、目的
数仓的数据源是Kafka,因此离线数仓需要用Flume采集Kafka中的数据到HDFS中
在实际项目中,不可能一直在Xshell中启动Flume任务,一是项目的Flume任务很多,二是一旦Xshell页面关闭Flume任务就会停止,这样非常不…

(二十八)大数据实战——Flume数据采集之kafka数据生产与消费集成案例
前言
本节内容我们主要介绍一下flume数据采集和kafka消息中间键的整合。通过flume监听nc端口的数据,将数据发送到kafka消息的first主题中,然后在通过flume消费kafka中的主题消息,将消费到的消息打印到控制台上。集成使用flume作为kafka的生产…
【Kafka-3.x-教程】-【六】Kafka 外部系统集成 【Flume、Flink、SpringBoot、Spark】
【Kafka-3.x-教程】专栏:
【Kafka-3.x-教程】-【一】Kafka 概述、Kafka 快速入门 【Kafka-3.x-教程】-【二】Kafka-生产者-Producer 【Kafka-3.x-教程】-【三】Kafka-Broker、Kafka-Kraft 【Kafka-3.x-教程】-【四】Kafka-消费者-Consumer 【Kafka-3.x-教程】-【五…

Flume基础知识点
Flume的简介 Flume是一种分布式的,可靠的、高可用的服务,用于有效地收集,聚合和移动大量日志数据。它具有基于流数据流的简单灵活的体系结构。它具有可调整的可靠性机制以及许多故障转移和恢复机制,具有强大的功能和容错能力。它使…

Flume的简介、原理与安装
1、前言
flume是由cloudera软件公司产出的可分布式日志收集系统,后与2009年被捐赠了apache软件基金会,为hadoop相关组件之一。尤其近几年随着flume的不断被完善以及升级版本的逐一推出,特别是flume-ng;同时flume内部的各种组件不断丰富&…

使用 Flume 将 CSV 数据导入 Kafka:实现实时数据流
使用 Flume 将 CSV 数据导入 Kafka:实现实时数据流
文介绍了如何使用 Apache Flume 将 CSV 格式的数据从本地文件系统导入到 Apache Kafka 中,以实现实时数据流处理。通过 Flume 的配置和操作步骤,我们可以轻松地将数据从 CSV 文件中读取并发…

数仓开发之Flume《一》:Flume的概述及安装
目录
1. 🥙Flume概述
1.1 Flume简介
1.2 Flume的架构
1. 🧀agent介绍
2. Agent 主要有 3 个部分组成,Source、Channel、Sink。
🥗2.1 Source
🥗2.2 Sink
🥗2.3 Channel
3. 🧀Flume 自…
Flume的安装配置
***:Flume目前只有Linux系统的启动脚本,没有Windows环境的启动脚本 1、准备安装包,上传到虚拟机的某一目录下(随意,但尽量放到某一固定目录下,我的在:/root/softwares/) flume包官网…
第二证券:今日投资前瞻:PPP迎来新机制,消费电池需求有望迎来复苏
11月8日,两市股指盘中轰动回落,尾盘逐渐止跌。到收盘,沪指跌0.16%报3052.37点,深成指微跌0.04%报10052.09点,创业板指涨0.02%报2023.13点,科创50指数涨0.92%;两市估计成交10366亿元,…
大数据技术之Flume(超级详细)
大数据技术之Flume(超级详细)
第1章 概述
1.1 Flume定义 Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。 1.2 Flume组成架构 Flume组成架构如…

Flume学习---3、自定义Interceptor、自定义Source、自定义Sink
1、自定义Interceptor
1、案例需求 使用 Flume 采集服务器本地日志,需要按照日志类型的不同,将不同种类的日志发往不同的分析系统。 2、需求分析 在实际的开发中,一台服务器产生的日志类型可能有很多种,不同类型的日志可能需要发…
尚硅谷大数据项目《在线教育之实时数仓》笔记006
视频地址:尚硅谷大数据项目《在线教育之实时数仓》_哔哩哔哩_bilibili 目录
第9章 数仓开发之DWD层
P041
P042
P043
P044
P045
P046
P047
P048
P049
P050
P051
P052 第9章 数仓开发之DWD层
P041 9.3 流量域用户跳出事务事实表 P042 DwdTrafficUserJum…
Apacha Flume
0目录 1.Flume概述 2.Flume安装部署 3.案例1 4.案例2 5.案例3 1.Flume概述 1.1 Flume定义 Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。 1.2 Flume基础架构 Flume组…

二百一十一、Flume——Flume实时采集Linux中的Hive日志写入到HDFS中(亲测、附截图)
一、目的
为了实现用Flume实时采集Hive的操作日志到HDFS中,于是进行了一场实验
二、前期准备
(一)安装好Hadoop、Hive、Flume等工具 (二)查看Hive的日志在Linux系统中的文件路径
[roothurys23 conf]# find / -name…

500元价位开放式耳机哪款好用、百元价位开放式耳机推荐
经常佩戴入耳式耳机的朋友应该都遇到过耳朵肿胀的感觉,这个时候,就是耳朵在告诉你,该休息一会了。如果耳朵里经常塞着耳机听歌,时间久了很容易引起听力衰退等问题,这是不可逆的伤害。各位朋友如果和我一样每天都戴着耳…

大数据面试题 —— Flume
目录 介绍 FlumeFlume 架构请说一下你提到的几种 source 的不同点Flume 传输数据时如何保证数据一致性TailDir 为什么可以断点重传说下Flume事务机制Sink 消费能力弱,Channel 会不会丢失数据数千个Flume要怎么统一配置,修改就分发吗Flume一个节点宕机了怎…
【数仓】flume软件安装及配置
相关文章
【数仓】基本概念、知识普及、核心技术【数仓】数据分层概念以及相关逻辑【数仓】Hadoop软件安装及使用(集群配置)【数仓】Hadoop集群配置常用参数说明【数仓】zookeeper软件安装及集群配置【数仓】kafka软件安装及集群配置【数仓】flume软件安…
二百一十五、Flume——Flume拓扑结构之复制和多路复用的开发案例(亲测,附截图)
一、目的
对于Flume的复制和多路复用拓扑结构,进行一个小的开发测试
二、复制和多路复用拓扑结构 (一)结构含义
Flume 支持将事件流向一个或者多个目的地。
(二)结构特征
这种模式可以将相同数据复制到多个channe…
Flume最简单使用
文章目录 一、简介1、定义2、基础架构 二、快速入门1、解压Flume2、案例一:监控端口号3、案例二:将空目录下文件 三、Flume进阶1、Flume事务2、Flume Agent内部原理3、案例一:监控日志4、案例二:多路复用和拦截器适应4.1 原理4.2 …

Flume 拦截器概念及自定义拦截器的运用
文章目录 Flume 拦截器拦截器的作用拦截器运用1.创建项目2.实现拦截器接口3.编写事件处理逻辑4.拦截器构建5.打包与上传6.编写配置文件7.测试运行 Flume 拦截器
在 Flume 中,拦截器(Interceptors)是一种可以在事件传输过程中拦截、处理和修改…

Flume实时读取本地/目录文件到HDFS
目录
一、准备工作
二、实时读取本地文件到HDFS
(一)案例需求
(二)需求分析
(三)实现步骤
三、实时读取目录文件到HDFS
(一)案例需求
(二)需求分析
…

关于Flume-Kafka-Flume的模式进行数据采集操作
测试是否连接成功: 在主节点flume目录下输入命令: bin/flume-ng agent -n a1 -c conf/ -f job/file_to_kafka.conf -Dflume.root.loggerinfo,console # 这个file_to_kafka.conf文件就是我们的配置文件 然后在另一台节点输入命令进行消费数据: kafka-cons…

一百九十一、Flume——Flume配置文件各参数含义(持续完善中)
一、目的
在实际项目的开发过程中,不同Kafka主题的数据规模、数据频率,需要配置不同的Flume参数,而这一切的调试、配置工作,都要建立在对Flume配置文件各参数含义的基础上
二、Flume各参数及其含义
(一)…
十、flume的安装
1.解压 2.改名 3.修改权限 4.编辑环境变量并source export FLUME_HOME/usr/local/flume export PATH$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$HBASE_HOME/bin:$SQOOP_HOME/bin:$PIG_HOME/bin:$FLUME_HOME/bin 5.配置 6.查看版本 7.启动Hadoo…
【数仓】通过Flume+kafka采集日志数据存储到Hadoop
相关文章
【数仓】基本概念、知识普及、核心技术【数仓】数据分层概念以及相关逻辑【数仓】Hadoop软件安装及使用(集群配置)【数仓】Hadoop集群配置常用参数说明【数仓】zookeeper软件安装及集群配置【数仓】kafka软件安装及集群配置【数仓】flume软件安…

(二十二)大数据实战——Flume数据采集之故障转移案例实战
前言
本节内容我们完成Flume数据采集的故障转移案例,使用三台服务器,一台服务器负责采集nc数据,通过使用failover模式的Sink处理器完成监控数据的故障转移,使用Avro的方式完成flume之间采集数据的传输。整体架构如下:…

Flume多路复用模式把接收数据注入kafka 的同时,将数据备份到HDFS目录
启动hadoop、在hdfs中创建需要访问的目录配置Hadoop的核心配置文件core-site.xml:设置Hadoop的核心配置参数,例如NameNode的地址、数据块大小、副本数量等。示例配置如下:<configuration><property><name>fs.defaultFS<…

百元开放式耳机推荐哪款比较好、百元开放式耳机推荐
开放式耳机由于其不入耳的设计,佩戴时不会压迫耳腔,因此长时间佩戴时没有压力。加之因为开放式耳机的发声原理是通过空气传导的原理,音质会比较自然舒适,更加饱满,氛围感更强,会更符合我们正常人的听觉&…

【大数据之Flume】七、Flume进阶之自定义Sink
(1)概述: Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。 Sink 是完全事务性的。在从 Channel 批量删除数据之前,每个 Sink 用 Chan…

Flume自定义拦截器 - ETL拦截器和分类拦截器
水善利万物而不争,处众人之所恶,故几于道💦 目录
一、拦截器(Interceptor)和选择器(Selector) 拦截器(Interceptor) 选择器(Selector)
二、自定…
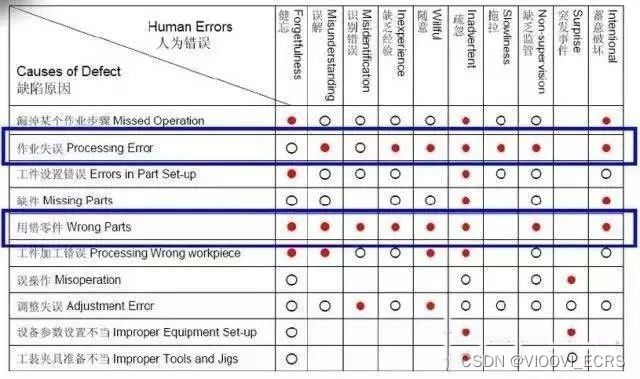
【精益生产】生产线上怎么做“防错”? 视与视ECRS工时分析软件
今天和大家聊一聊“防错”。在几年前,师父第一次把我独立地扔到一条座椅装配的生产线上去审核。
看些十几道工序,几十台设备在那有条不紊的运转着。款式各异的条码,测量设备上花花绿绿的信号看得我眼花缭乱,丝毫不知道该从哪下手…
Flume1.9基础学习
文章目录 一、Flume 入门概述1、概述2、Flume 基础架构2.1 Agent2.2 Source2.3 Sink2.4 Channel2.5 Event 3、Flume 安装部署3.1 安装地址3.2 安装部署 二、Flume 入门案例1、监控端口数据官方案例1.1 概述1.2 实现步骤 2、实时监控单个追加文件2.1 概述2.2 实现步骤 3、实时监…
大数据技术学习笔记(十一)—— Flume
目录 1 Flume 概述1.1 Flume 定义1.2 Flume 基础架构 2 Flume 安装3 Flume 入门案例3.1 监控端口数据3.2 实时监控单个追加文件3.3 实时监控目录下多个新文件3.4 实时监控目录下的多个追加文件 4 Flume 进阶4.1 Flume 事务4.2 Flume Agent 内部原理4.3 Flume 拓扑结构4.3.1 简单…
GZ033 大数据应用开发赛题第05套
2023年全国职业院校技能大赛
赛题第05套 赛项名称: 大数据应用开发
英文名称: Big Data Application Development
赛项组别: 高等职业教育组
赛项编号: GZ033 …
数据采集项目之业务数据(三)
1. Maxwell框架
开发公司为Zendesk公司开源,用java编写的MySQL变更数据抓取软件。内部是通过监控MySQL的Binlog日志,并将变更数据以JSON格式发送到Kafka等流处理平台。
1.1 MySQL主从复制
主机每次变更数据都会生成对应的Binlog日志,从机可…
Flume (三) Configuration
Configuration
正如前面部分所述,Flume代理程序配置是从类似于具有分层属性设置的Java属性文件格式的文件中读取的。
Defining the flow
要在单个代理中定义流,您需要通过channel连接sources 和sinks 。 您需要列出给定agent的sources,sin…
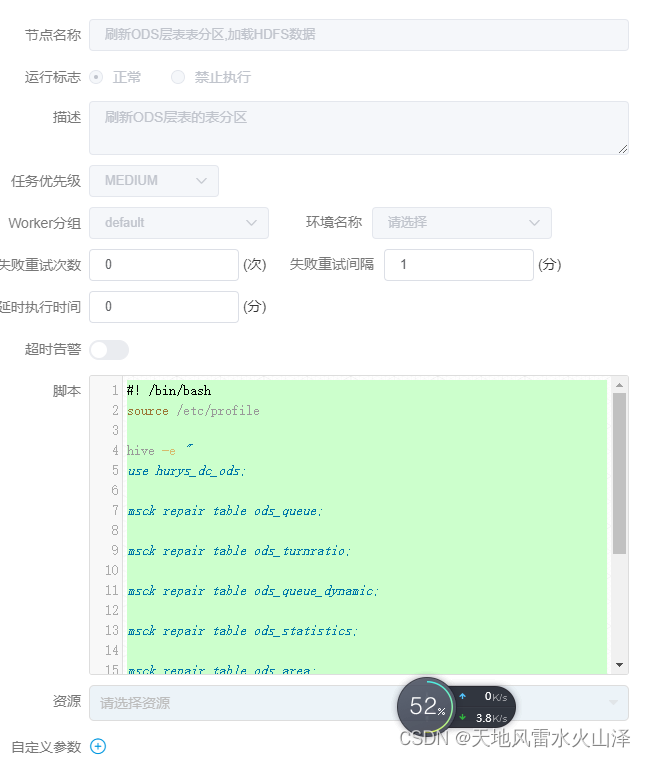
二百二十九、离线数仓——离线数仓Hive从Kafka、MySQL到ClickHouse的完整开发流程
一、目的
为了整理离线数仓开发的全流程,算是温故知新吧
离线数仓的数据源是Kafka和MySQL数据库,Kafka存业务数据,MySQL存维度数据
采集工具是Kettle和Flume,Flume采集Kafka数据,Kettle采集MySQL数据
离线数仓是Hi…

Flume学习笔记(3)—— Flume 自定义组件
前置知识: Flume学习笔记(1)—— Flume入门-CSDN博客 Flume学习笔记(2)—— Flume进阶-CSDN博客 Flume 自定义组件
自定义 Interceptor
需求分析:使用 Flume 采集服务器本地日志,需要按照日志…

0301taildir-source报错-flume-大数据
1 基础环境简介
linux系统:centos,前置安装:jdk、hadoop、zookeeper、kafka,版本如下
软件版本描述centos7linux系统发行版jdk1.8java开发工具集hadoop2.10.0大数据生态基础组件zookeeper3.5.7分布式应用程序协调服务kafka3.0分…
Qt中用thrift验证flume
一.flume简介
flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。 在flume中分为了3个组件,分别为source,channel和sink。 Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种…
仅2万粉,带了2.6万件的货!TikTok Shop美区达人周榜(11.13-11.19)
11月24日,TikTok Shop近日公布了美国市场和英国市场的全托管黑五大促战绩。数据显示,11月14日至11月20日,其美国市场的订单量环比10月20日-10月26日增长了205%。
家居户外热销品有:数码触摸屏相框、毛绒地毯、家居毛毯。黑马商品…
测试开发 - 一面凉经 - 好未来
2024.3.09 约面
2024.3.11 面试
自我介绍
学校地点确认
毕业年份确认
项目介绍 - 聊天平台日志分析
具体分析了哪些指标
没有针对内容做分析吗
可视化展示是展示的什么内容呀
为什么作为一款聊天平台,用户常用词没有分析呢
用户是哪里来的
实习时自动化测…

实验四 Spark Streaming编程初级实践
一、Flume简介
数据流 :数据流通常被视为一个随时间延续而无限增长的动态数据集合,是一组顺序、大量、快速、连续到达的数据序列。通过对流数据处理,可以进行卫星云图监测、股市走向分析、网络攻击判断、传感器实时信号分析。 二、Flume安装…
【数仓】flume常见配置总结,以及示例
相关文章
【数仓】基本概念、知识普及、核心技术【数仓】数据分层概念以及相关逻辑【数仓】Hadoop软件安装及使用(集群配置)【数仓】Hadoop集群配置常用参数说明【数仓】zookeeper软件安装及集群配置【数仓】kafka软件安装及集群配置【数仓】flume软件安…
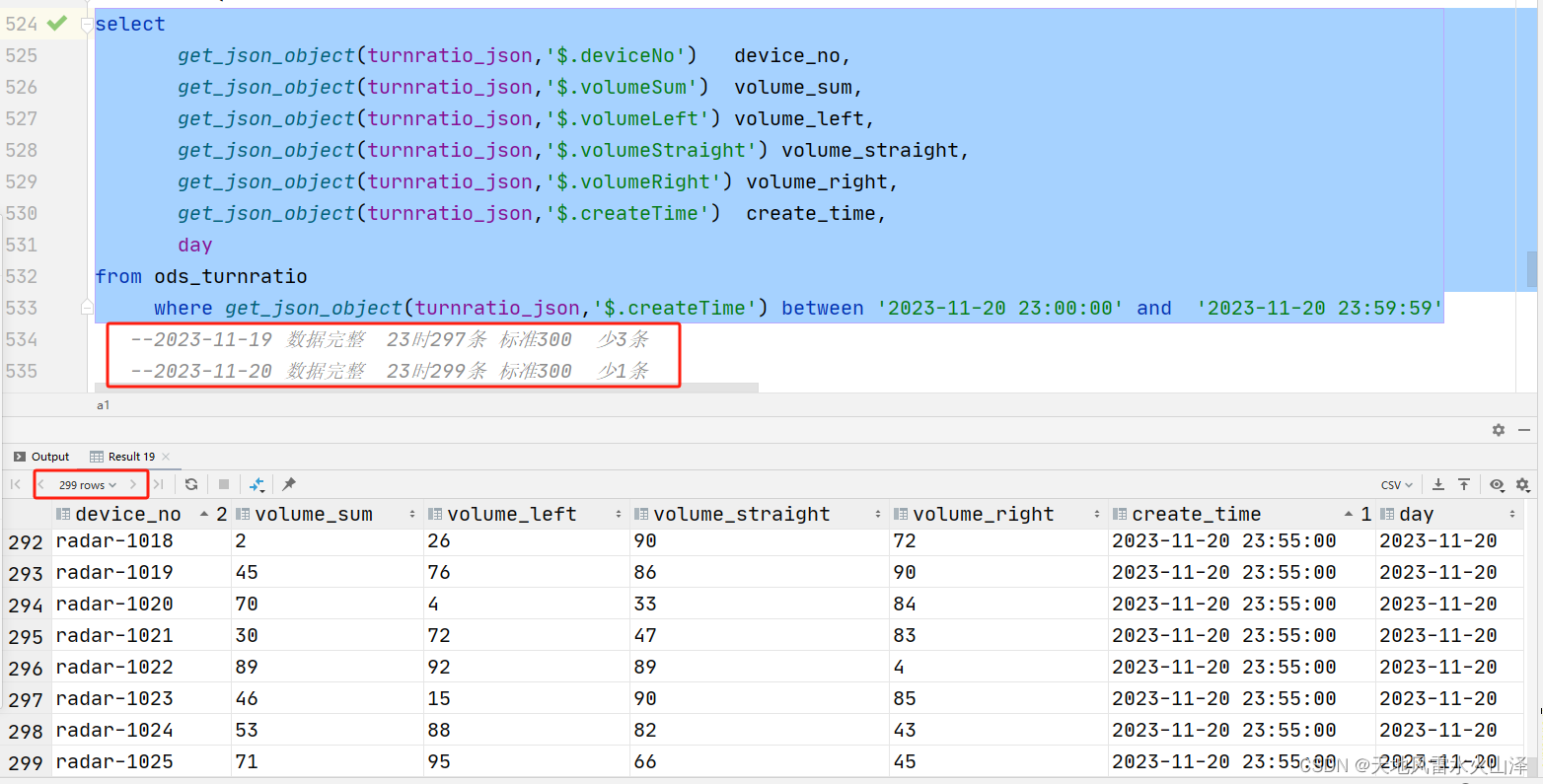
二百零三、Flume——Flume实时采集数据频率为1s的高频率Kafka数据直接写入ODS层表的HDFS文件路径下
一、目的
在离线数仓中,需要用Flume去采集Kafka中的数据,然后写入HDFS中。
由于每种数据类型的频率、数据大小、数据规模不同,因此每种数据的采集需要不同的Flume配置文件。玩了几天Flume,感觉Flume的使用难点就是配置文件
二、…
【大数据之Flume】八、Flume 数据流监控
1 Ganglia 的安装与部署 (1)安装 安装规划: 在hadoop102、103、104安装epel-release:
sudo yum -y install epel-release在102安装:web、gmetad、gmod:
sudo yum -y install ganglia-gmetad
sudo yum -y…
大数据技术——Flume实战案例
实战案例目录1. 复制和多路复用1.1 案例需求1.2 需求分析1.3 实现操作2. 负载均衡和故障转移2.1 案例需求2.2 需求分析2.3 实现操作3. 聚合操作3.1 案例需求3.2 需求分析3.3 实现操作1. 复制和多路复用
1.1 案例需求 使用 Flume-1 监控文件变动,Flume-1 将变动内容…
Flume进阶学习!
本文图片来自于8.flume实时监控文件hdfs sink使用演示_哔哩哔哩_bilibili
Apache Flume 的启动过程及其配置文件和脚本
在官网下载的Flume的压缩包中,.lib文件有大量的jar包,按道理说只有.lib文件就可以运行Flume程序了。只不过需要java -jar命令还要加…
Flume的安装部署及常见问题解决
1.安装地址
(1) Flume官网地址:http://flume.apache.org/ (2)文档查看地址:http://flume.apache.org/FlumeUserGuide.html (3)下载地址:http://archive.apache.org/dist…
flume安装及实战
flume官方下载地址:Welcome to Apache Flume — Apache Flume
一、flume安装
(1)解压至安装目录
tar -zxf ./apache-flume-1.9.0-bin.tar.gz -C /opt/soft/
(2)配置文件flume-env.sh
cd /opt/soft/flume190/conf
…
0-Flume(1.11.0版本)在Linux(Centos7.9版本)的安装(含Flume的安装包)
环境检查
#首先确认自己的Linux是Centos版本,运行命令
cat /etc/centos-release结果:CentOS Linux release 7.9.2009 (Core)
安装 Flume本身是由Java开发的,所以需要服务器上安装好JDK1.8(注意区分Linux还是Windows系统的JDk&a…
记录一个写自定义Flume拦截器遇到的错误
先说结论:
【结论1】配置文件中包名要写正确
vim flume1.conf
...
a1.sources.r1.interceptors.i1.type com.atguigu.flume.interceptor.MyInterceptor2$MyBuilder
...
标红的是包名,表黄的是类名,标蓝的是自己加的内部类名。这三个都…
Flume数据源与数据接收端的了解
1.Flume官方文档
https://flume.apache.org/releases/content/1.11.0/FlumeUserGuide.html#data-flow-model
2.Flume的配置主体框架
# example.conf:单节点 Flume 配置
# 1. 声明框架组件
# 将此代理上的组件命名为
# 数据源r1
a1.sources r1
# 数据终点k1
a…
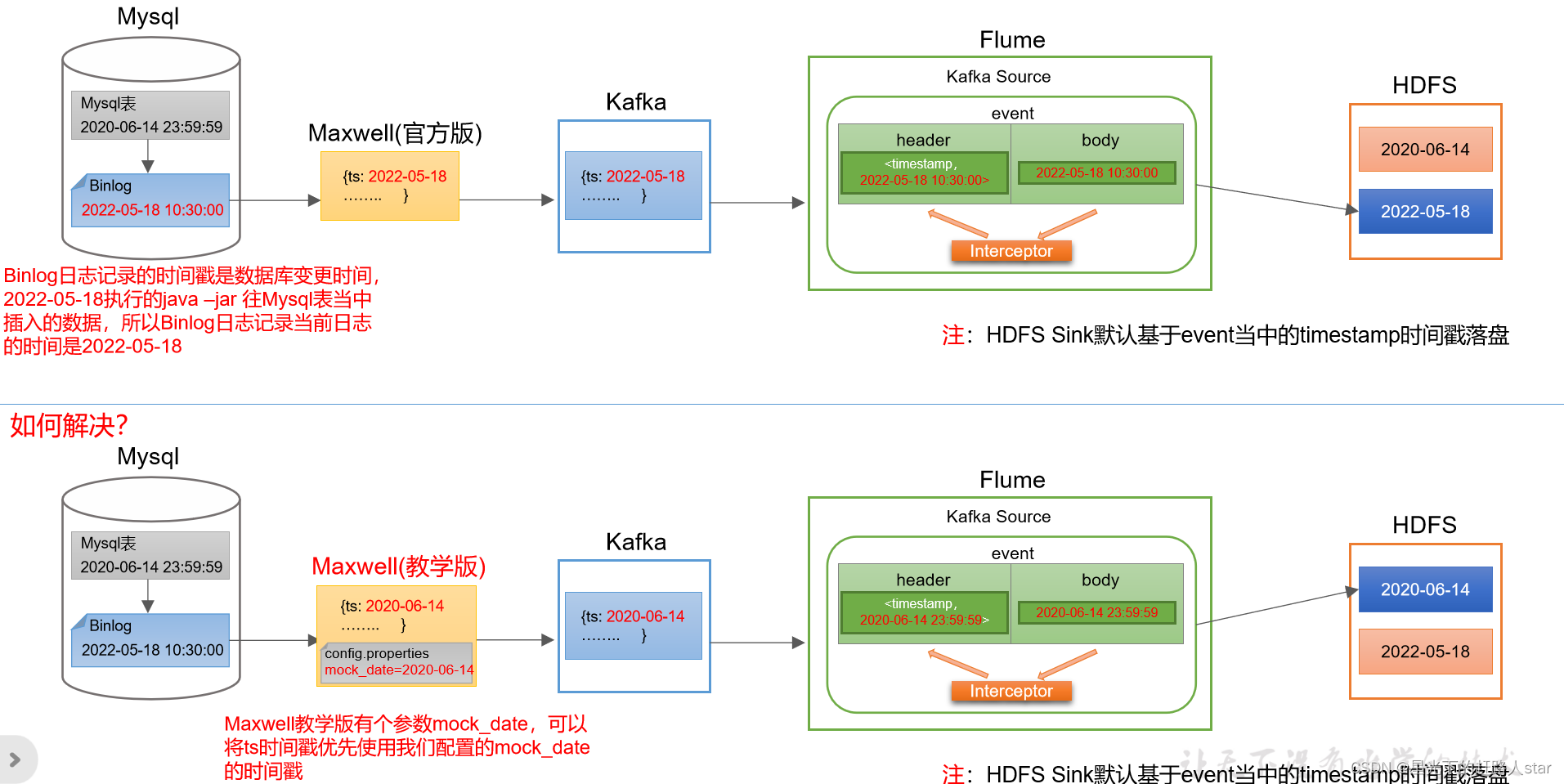
4、离线数仓数据同步策略(全量表数据同步、增量表数据同步、首日同步、采集通道脚本)
1、离线数仓同步数据
1.1 用户行为数据同步
1.1.1 数据通道
用户行为数据由Flume从Kafka直接同步到HDFS,由于离线数仓采用Hive的分区表按天统计,所以目标路径要包含一层日期。具体数据流向如下图所示。
1.1.2 日志消费Flume配置概述
按照规划&…
flume拦截器介绍
Flume是一个开源的、分布式的、可靠的、高效的海量数据采集、聚合和传输系统。其中,拦截器(Interceptor)是Flume中的一种组件,可以在数据(Event)流动的各个阶段对数据进行处理、过滤或转换,从而实现更为灵活、高效的数据采集和传输。
1、拦截…
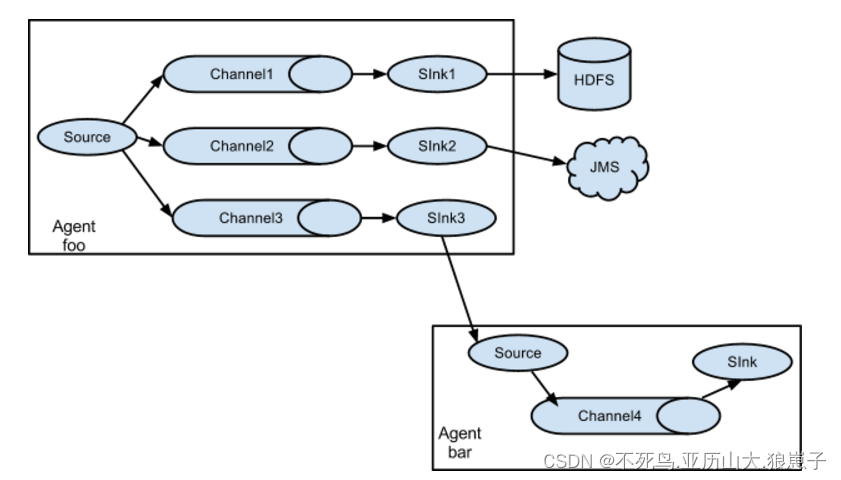
Apache Flume(5):多个agent模型
可以将多个Flume agent 程序连接在一起,其中一个agent的sink将数据发送到另一个agent的source。Avro文件格式是使用Flume通过网络发送数据的标准方法。 从多个Web服务器收集日志,发送到一个或多个集中处理的agent,之后再发往日志存储中心&…
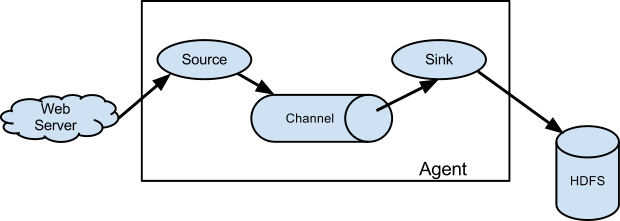
Flume (一) Introduction
Overview
Apache Flume是一个分布式、高可靠和高可用的, 用于收集、聚集和将来自不同来源的大量日志数据移动到一个中央数据仓库。
Apache Flume不仅仅局限于数据的聚集。由于数据是可定制的,Flume可用于传输大量事件数据,包括但不限于网络流量数据&am…
大数据项目之电商数仓、实时数仓同步数据、离线数仓同步数据、用户行为数据同步、日志消费Flume配置实操、日志消费Flume测试、日志消费Flume启停脚本
文章目录8. 实时数仓同步数据9. 离线数仓同步数据9.1 用户行为数据同步9.1.1 数据通道9.1.1.1 用户行为数据通道9.1.2 日志消费Flume配置概述9.1.2.1 日志消费Flume关键配置9.1.3 日志消费Flume配置实操9.1.3.1 创建Flume配置文件9.1.3.2 配置文件内容如下9.1.3.2.1 配置优化9.…
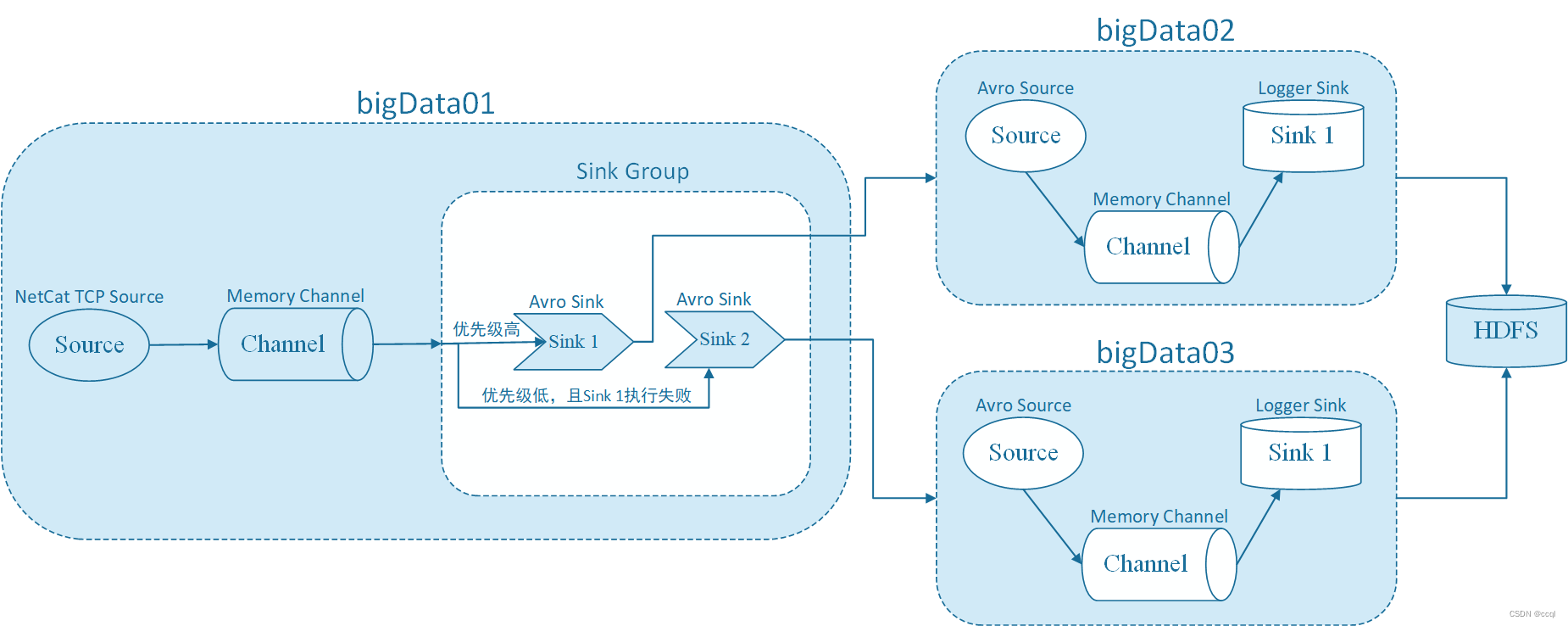
【Flume】高级组件之Sink Processors及项目实践(Sink负载均衡和故障转移)
文章目录 1. 组件简介2. 项目实践2.1 负载均衡2.1.1 需求2.1.2 配置2.1.3 运行 2.2 故障转移2.2.1 需求2.2.2 配置2.2.3 运行 1. 组件简介 Sink Processors类型包括这三种:Default Sink Processor、Load balancing Sink Processor和Failover Sink Processor。
Defa…
Flume 详细使用文档及案例
目录 Flume 使用文档简介安装前置条件下载安装配置SourceSink运行 结论 案例背景解决方案步骤一:安装 Flume步骤二:配置 Flume步骤三:启动 Flume步骤四:查看结果结论 Flume 使用文档
简介
Apache Flume 是一个分布式、可靠、高可…
Flume详解(2)
Flume
Sink
HDFS Sink 将数据写到HDFS上。数据以文件形式落地到HDFS上,默认是以FlumeData开头,可以通过hdfs.filePrefix来修改 HDFS Sink默认每隔30s会滚动一次生成一个文件,因此会导致在HDFS上生成大量的小文件,实际过程中&am…

【Flume】尚硅谷学习笔记
实时监控目录下多个新文件 本案例是将虚拟机本地文件进行实时监控,并将上传的数据实时上传到HDFS中。 TAILDIR SOURCE【实现多目录监控、断点续传】
监视指定的文件,一旦检测到附加到每个文件的新行,就几乎实时地跟踪它们。如果正在写入新行…
SparkStreaming整合KafkaFlume
文章目录代码已上传至githubhttps://github.com/2NaCl/sparkstreaming_kafka-flume-demo/我们首先来看一下架构的图,方便我们来了解并且复习一下之前所提到的知识。 由外部的软件实时产生一些数据,然后用flume实时对这些数据进行采集,利用Kaf…

Linux下Flume安装配置及简单使用
环境说明:
操作系统:CentOS6.9 64位
解压:
tar -xzvf apache-flume-1.7.0-bin.tar.gz创建软链接:
ln -s /opt/modules/apache-flume-1.6.0-cdh5.9.3-bin/ /opt/shortcut/flume这里不再添加环境变量
修改flume-env.sh配置文件:
# 先修改…
Flume从入门到精通一站式学习笔记
文章目录 什么是FlumeFlume的特性Flume高级应用场景Flume的三大核心组件Source:数据源channelsink Flume安装部署Flume的使用案例:采集文件内容上传至HDFS案例:采集网站日志上传至HDFS 各种自定义组件例如:自定义source例如&#…
大数据架构:flume-ng+Kafka+Storm+HDFS 实时系统组合
个人观点:大数据我们都知道hadoop,但并不都是hadoop.我们该如何构建大数据库项目。对于离线处理,hadoop还是比较适合的,但是对于实时性比较强的,数据量比较大的,我们可以采用Storm,那么Storm和什…
Flume系列:案例-Flume复制(Replicating)和多路复用(Multiplexing)
目录
Apache Hadoop生态-目录汇总-持续更新
1:案例流程描述 2:实现步骤:
2.1:实现flume1.conf
2.2:实现flume2_hdfs.conf
2.3:实现flume3_dir.conf
3:启动传输链路 Apache Hadoop生态-目录…

flume异常关闭文件修复方法
flume在从kafka采集数据后,会将数据写入到hdfs文件中。在写入过程中,由于集群负载、资源或者网络原因会导致文件没有正常关闭,即文件表现为tmp格式,这种格式的文件从hdfs往hive分区load数据时,会导致数据无法查询问题。 flume写…

SparkStreaming整合flume
文章目录目标一:Flume-style Push-based Approach目标二:Push-based Approach using a Custom SinkSparkStreaming整合flume有两种方式,下面会一一列举这两个Demo github地址:https://github.com/2NaCl/spark_flume_demo
目标一&…

二百一十七、Flume——Flume拓扑结构之聚合的开发案例(亲测,附截图)
一、目的
对于Flume的聚合拓扑结构,进行一个开发测试
二、聚合 (一)结构含义
这种模式是我们最常见的,也非常实用。日常web应用通常分布在上百个服务器,大者甚至上千个、上万个服务器产生的日志,处理起来…
【Spark Streaming】日志收集框架Flume的学习
日志收集框架Flume
概览
Apache Flume是一个分布式,可靠且可用的系统,用于有效地收集,聚合大量日志数据并将其从许多不同的源移动到集中式数据存储中。Apache Flume的使用不仅限于日志数据聚合。由于数据源是可定制的,因此Flume…

Flume学习笔记(2)—— Flume进阶
Flume进阶
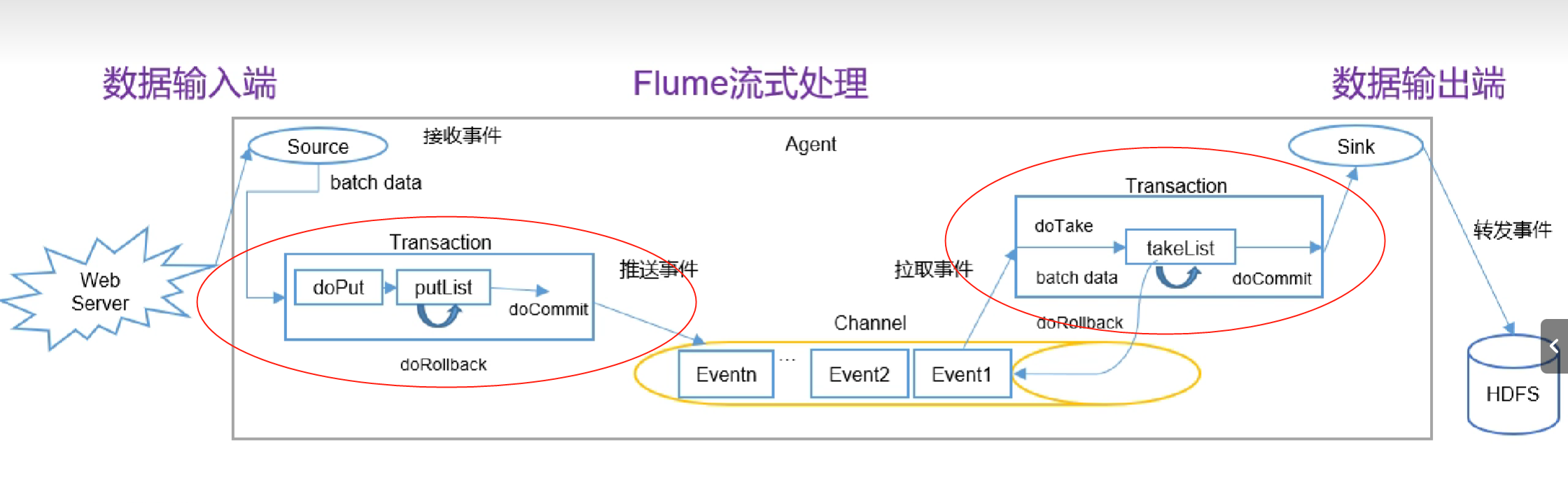
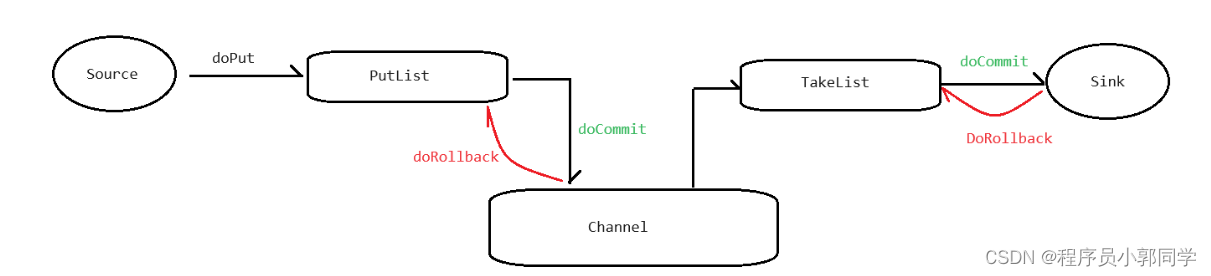
Flume 事务
事务处理流程如下: Put
doPut:将批数据先写入临时缓冲区putListdoCommit:检查channel内存队列是否足够合并。doRollback:channel内存队列空间不足,回滚数据
Take
doTake:将数据取…

Flume基础知识(一):Flume组成原理与架构
1. Flume定义
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。 Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS。 2. Fl…
2023_Spark_实验二十九:Flume配置KafkaSink
实验目的:掌握Flume采集数据发送到Kafka的方法
实验方法:通过配置Flume的KafkaSink采集数据到Kafka中
实验步骤: 一、明确日志采集方式
一般Flume采集日志source有两种方式:
1.Exec类型的Source
可以将命令产生的输出作为源&…
数据迁移工具之Flume
文章目录一、Flume1、Flume的架构1.Agent2.Source3. Sink4.Channel5. Event2、flume内部数据传输的封装形式3、 Transaction:事务控制机制4、 拦截器二、Flume安装1、启动命令三、Flume的端口数据监听1、切换目录并创建配置文件2、配置信息3、打开Flume监听窗口4、使…
GZ033 大数据应用开发赛题第07套
2023年全国职业院校技能大赛 赛题第07套 赛项名称: 大数据应用开发 英文名称: Big Data Application Development 赛项组别: 高等职业教育组 赛项编号: GZ033 …

大数据组件之Flume(1)
关于flume 的介绍 我是围绕三个方面来说的 是什么 去哪下 怎么玩
1. flume是什么 Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。flume可以聚合大量日志数据并将其从许…
Flume日志采集流程(log->kafka->hdfs)
埋点数据:用户访问业务服务器如Nginx,利用log4j的技术,将客户端的埋点数据以日志的形式记录在文件中
服务器日志文件——>HDFS文件
日志文件——>Flume(agent source(interceptor) channel)——>kafka topic ——> Flume(agent…
GZ033 大数据应用开发赛题第06套
2023年全国职业院校技能大赛 赛题第06套 赛项名称: 大数据应用开发 英文名称: Big Data Application Development 赛项组别: 高等职业教育组 赛项编号: GZ033 …
Kafka整合Flume
大数据进行流式数据处理的时候Flume采集数据,Kafka消费数据,Spark Streaming处理数据是一种非常常见的架构,这里记录一下Kafka整合Flume的不过,以备后用
这里默认已经安装好了Kafka和Flume,不再介绍,大家可…
数据开发 - 面经(已OC) - 北京中海通
投递流程:
2023.12.28 Boss 打招呼
2024.1.3 约面
2024.1.4 上午面试 (手机端腾讯会议)
2024.1.5 上午 通知面试通过
腾讯会议手机端无法和录影机同时运行,录音无效,之后注意使用电脑面试
面试流程:首…

(二十三)大数据实战——Flume数据采集之采集数据聚合案例实战
前言
本节内容我们主要介绍一下Flume数据采集过程中,如何把多个数据采集点的数据聚合到一个地方供分析使用。我们使用hadoop101服务器采集nc数据,hadoop102采集文件数据,将hadoop101和hadoop102服务器采集的数据聚合到hadoop103服务器输出到…
flume配置文件后不能跟注释!!
先总结:Flume配置文件后面,不能跟注释,可以单起一行写注释 报错代码:
[ERROR - org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:158)] Unable to deliver event. Exception follows.
org.apache.flume.EventDel…
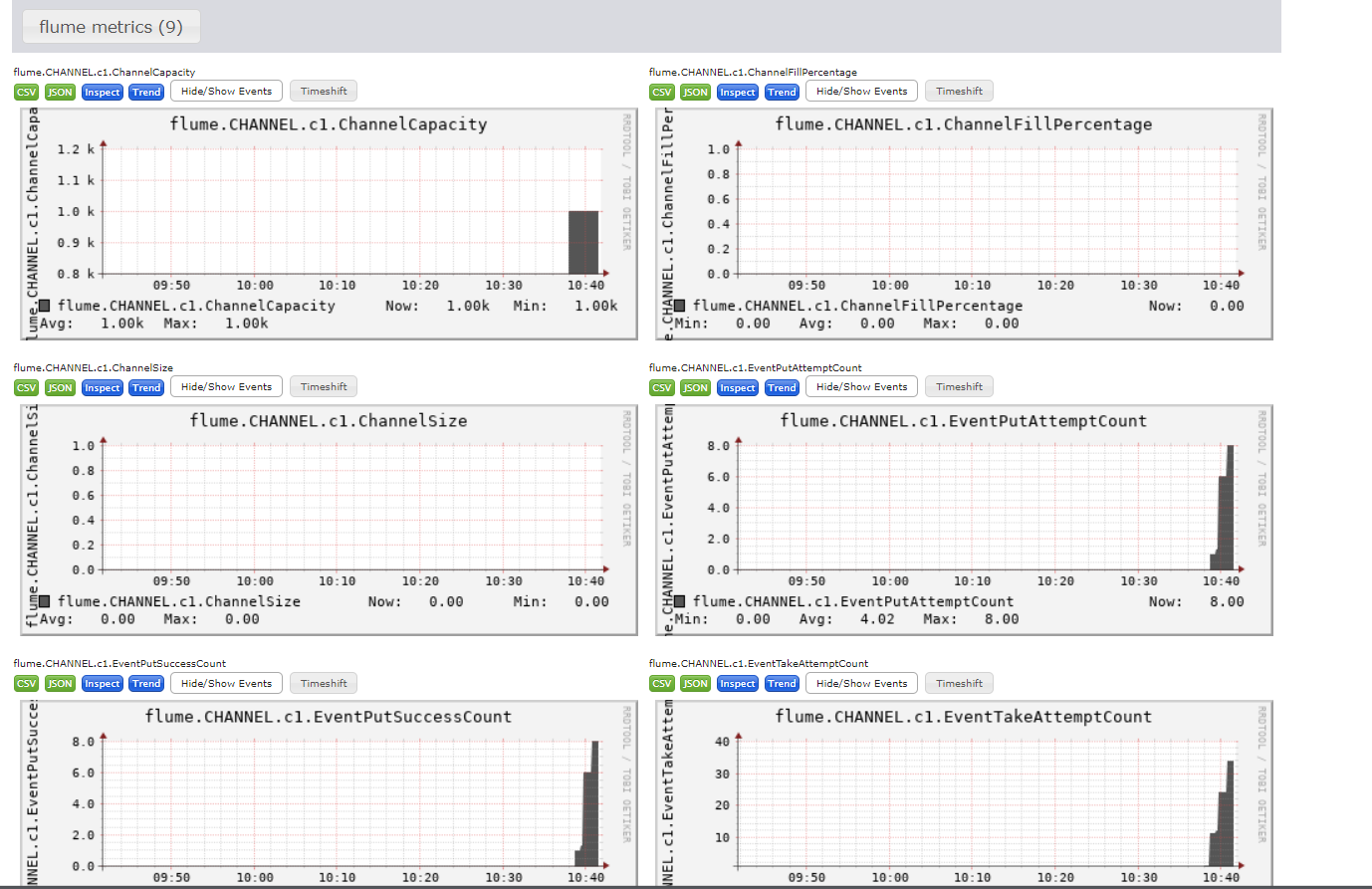
Flume学习笔记(4)—— Flume数据流监控
前置知识: Flume学习笔记(1)—— Flume入门-CSDN博客 Flume学习笔记(2)—— Flume进阶-CSDN博客 Flume 数据流监控 Ganglia 的安装与部署
Ganglia 由 gmond、gmetad 和 gweb 三部分组成。
gmond(Ganglia …

运动耳机平价的哪个牌子好用?运动耳机平价推荐
我作为一个爱运动的人来说,一年四季都会去跑步,这似乎是个习惯。但是跑步旅程还是较为枯燥的,加上后面的体力逐渐耗尽,总是会让跑步者开心不起来,所以,一款可以缓解运动过程中无聊的高品质的运动耳机就显得…
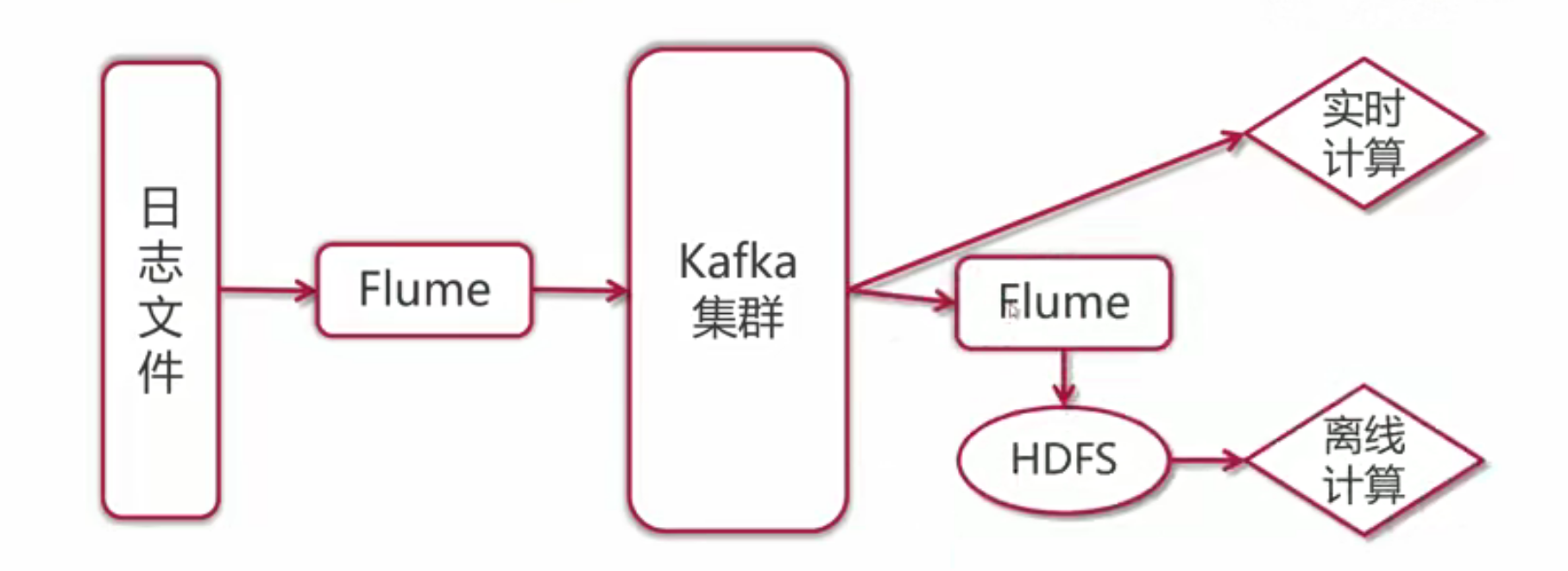
Flume集成Kafka
之前提到Flume可以直接采集数据存储到HDFS中,那为什么还要引入Kafka这个中间件呢,这个是因为在实际应用场景中,我们既需要实时计算也需要离线计算。 Kfka to HDFS配置
# Name the components on this agent
a1.sources r1
a1.sinks k1
a1.…

flume介绍及安装
一、什么是flume Flume是Cloudera提供的日志收集系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种storage。Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传…

Apache Flume
Apache Flume
一、概述
http://flume.apache.org/
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data.
Flume分布式、可靠、高效的数据采集、聚合和传输工具。具备容错和故障恢复…

flume1.11.0安装部署
1、准备安装包apache-flume-1.11.0-bin.tar.gz;
上传; 2、安装flume-1.11.0; 解压;
tar -zxvf apache-flume-1.11.0-bin.tar.gz -C /opt/server 进入conf目录,修改flume-env.sh,配置JAVA_HOME;…
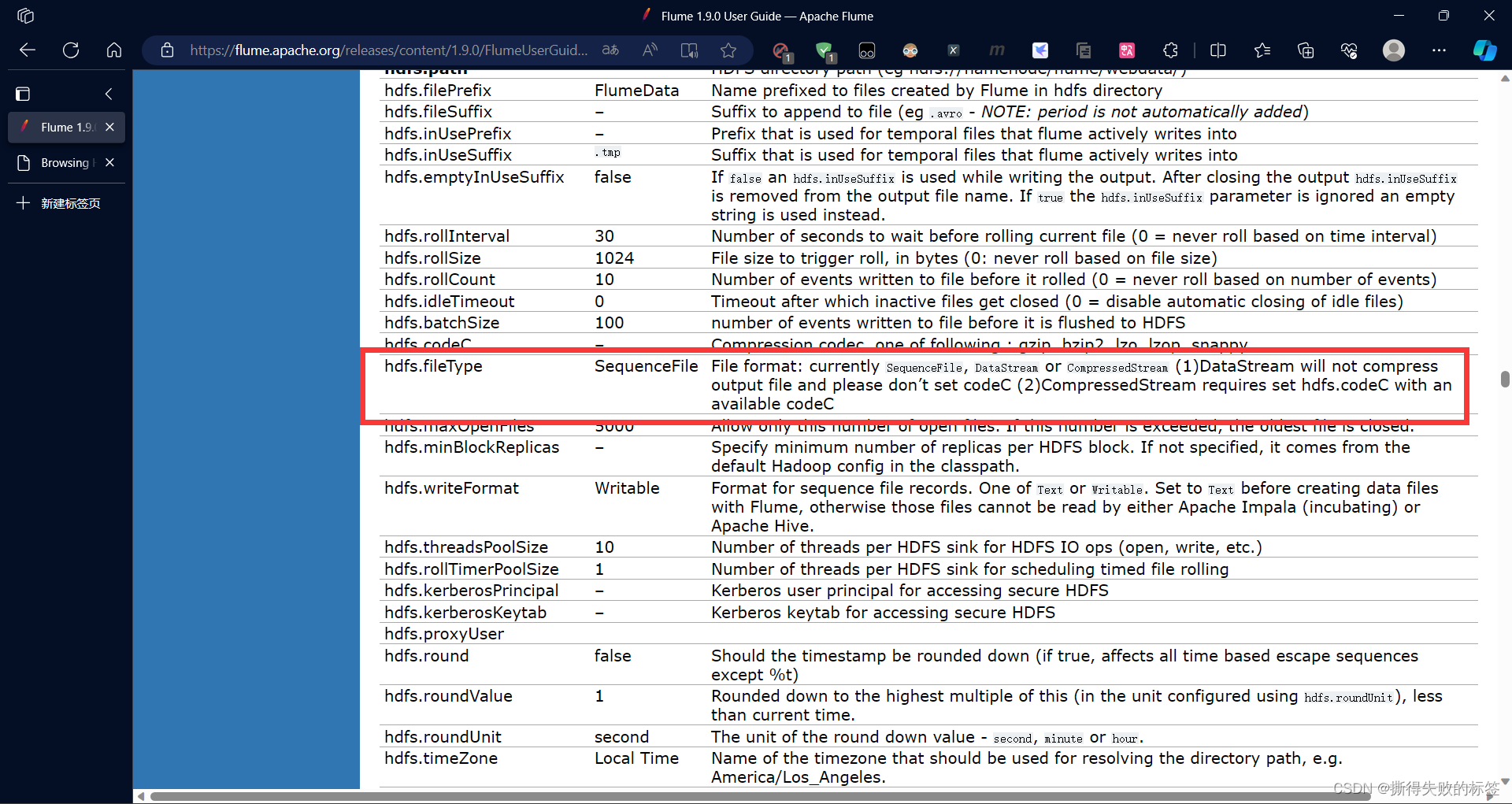
Flume 安装部署
文章目录 Flume 概述Flume 安装部署官方网址下载安装配置文件启动 Flume 进程启动报错输出文件乱码问题 Flume 概述
Flume(Apache Flume)是一个开源的分布式日志收集、聚合和传输系统,属于 Apache 软件基金会的项目之一。其主要目标是简化大…
一百七十二、Flume——Flume采集Kafka数据写入HDFS中(亲测有效、附截图)
一、目的
作为日志采集工具Flume,它在项目中最常见的就是采集Kafka中的数据然后写入HDFS或者HBase中,这里就是用flume采集Kafka的数据导入HDFS中
二、各工具版本
(一)Kafka
kafka_2.13-3.0.0.tgz
(二)…
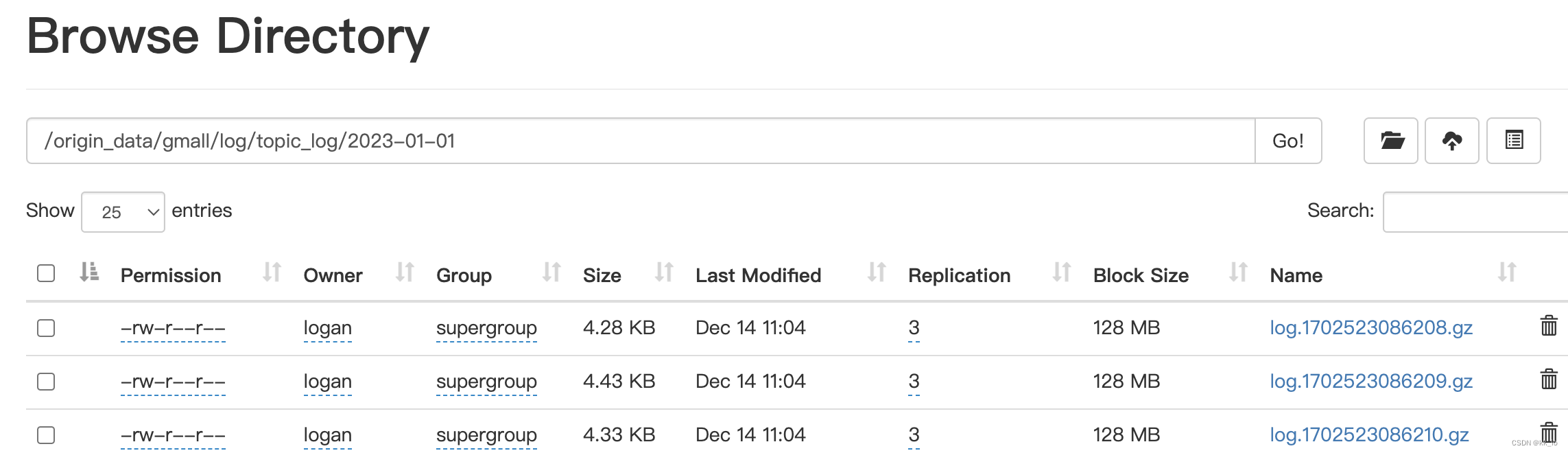
07用户行为日志数据采集
用户行为数据由Flume从Kafka直接同步到HDFS,由于离线数仓采用Hive的分区表按天统计,所以目标路径要包含一层日期。具体数据流向如下图所示。 按照规划,该Flume需将Kafka中topic_log的数据发往HDFS。并且对每天产生的用户行为日志进行区分&am…

Flume系列:Flume组件架构
目录
Apache Hadoop生态-目录汇总-持续更新
一:Flume 概述
二:Flume 基础架构 2.1:Agent
2.2:Source
2.3:Sink
2.4:Channel
1) Memory Channel
2) File Channel
3) Kafka Channel
2.5:…

Flume(二)【Flume 进阶使用】
前言 学数仓的时候发现 flume 落了一点,赶紧补齐。
1、Flume 事务 Source 在往 Channel 发送数据之前会开启一个 Put 事务:
doPut:将批量数据写入临时缓冲区 putList(当 source 中的数据达到 batchsize 或者 超过特定的时间就会…
1-Flume中agent的source
Flume(1.11.0版本)
简介
概述 Flume本身是由Cloudera公司开发的后来贡献给了Apache的一套针对日志数据进行收集(collecting)、汇聚(aggregating)和传输(moving)的机制 Flume本身提供了简单且灵活的结构来完成日志数据的传输 Flume有两大版本&#x…
Flume入门概述及安装部署
目录 一、Flume概述1.1 Flume定义1.2 Flume基础架构 二、Flume安装部署 一、Flume概述
1.1 Flume定义
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。
1.2 Flume基础…

电商风控系统(flink+groovy+flume+kafka+redis+clickhouse+mysql)
一.项目概览
电商的防止薅羊毛的风控系统
需要使用 groovy 进行风控规则引擎的编写 然后其它技术进行各种数据的 存储及处理 薅羊毛大致流程 如果单纯使用 if else在业务代码中进行风控规则的编写 那么 维护起来会比较麻烦 并且跟业务系统强绑定不合适 所以一般独立成一个单…
Flume(一)【Flume 概述】
前言 今天实在不知道学点什么好了,早上学了3个多小时的 Flink ,整天只学一门技术是很容易丧失兴趣的。那就学点新的东西 Flume,虽然 Kafka 还没学完,但是大数据生态圈的基础组件也基本就剩这倆了。
Flume 概述 生产环境中的数据一…
GZ033 大数据应用开发赛题第10套
2023年全国职业院校技能大赛
赛题第10套 赛项名称: 大数据应用开发
英文名称: Big Data Application Development
赛项组别: 高等职业教育组
赛项编号: GZ033 …
GZ033 大数据应用开发赛题第09套
2023年全国职业院校技能大赛
赛题第09套 赛项名称: 大数据应用开发
英文名称: Big Data Application Development
赛项组别: 高等职业教育组
赛项编号: GZ033 …

Flume官方文档笔记
为什么针对Flume写文档笔记呢,因为Flume Spark这两个框架都是我觉得写得很不错的,比Hadoop,Zookeeper之类的那些好很多,不多bb了。
Flume 入门简介
Flume is a distributed, reliable, and available service for efficiently c…
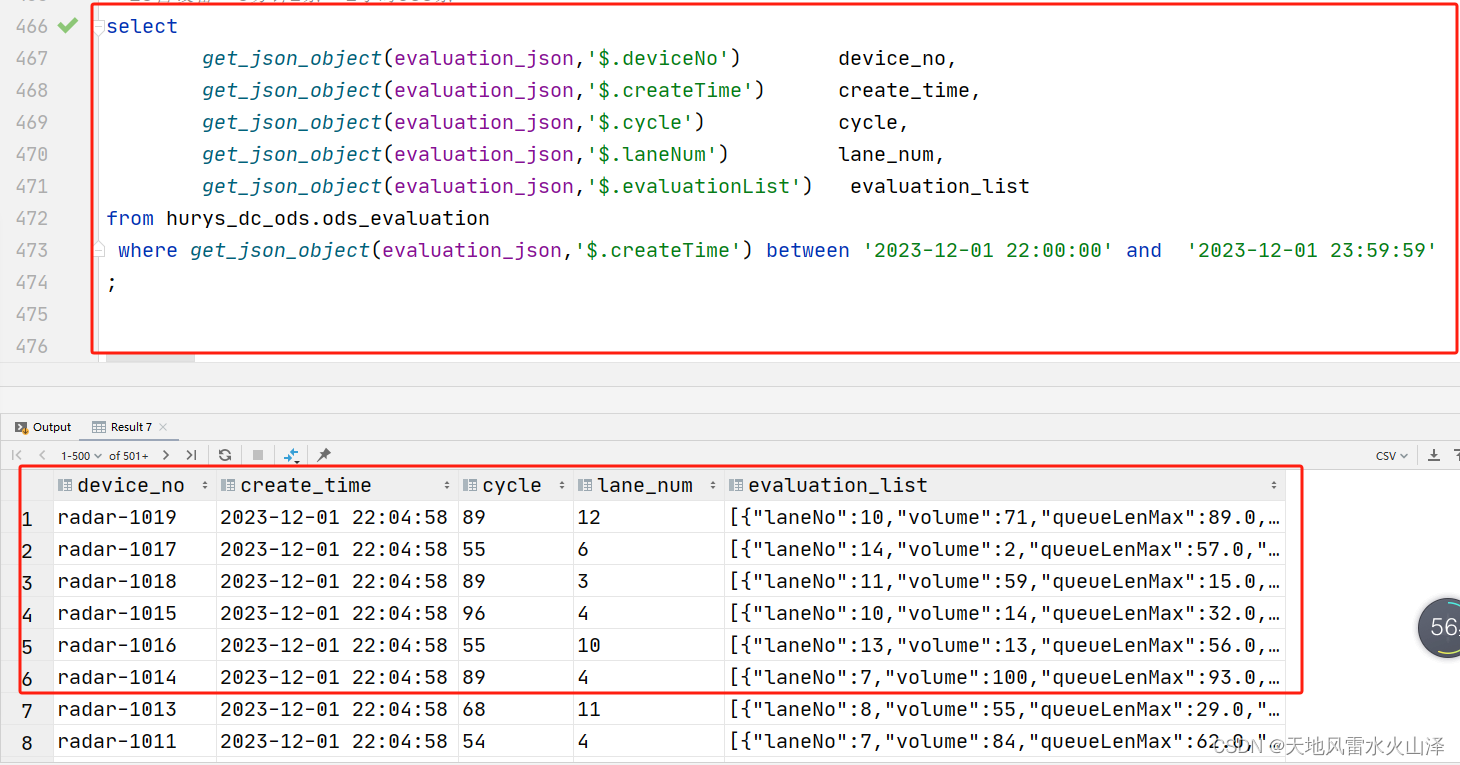
二百一十、Hive——Flume采集的JSON数据文件写入Hive的ODS层表后字段的数据残缺
一、目的
在用Flume把Kafka的数据采集写入Hive的ODS层表的HDFS文件路径后,发现HDFS文件中没问题,但是ODS层表中字段的数据却有问题,字段中的JSON数据不全
二、Hive处理JSON数据方式
(一)将Flume采集Kafka的JSON数据…

一文带你快速了解Flume!
Flume定义
Apache Flume 是一个分布式、可靠且高可用的系统,用于有效地收集、聚合和移动大量日志数据到集中式数据存储。它专为日志数据收集服务设计,但也适用于各种其他数据流场景(但主要还是.txt文本文件)。 Flume 支持多种数…
二百零六、Flume——Flume1.9.0单机版部署脚本(附截图)
一、目的
在实际项目部署时,要实现易部署易维护,需要把安装步骤变成安装脚本实现快速部署
二、部署脚本在Linux中文件位置 文件夹中只有脚本文件flume-install.sh和tar包apache-flume-1.9.0-bin.tar.gz
三、Flume安装脚本
#!/bin/bash #获取服务器名…
Kafka官方文档笔记
文章目录Kafka概述目标一:部署及使用单节点单Broker目标二:部署及使用单节点多Broker目标三:Kafka API编程--Producer端开发目标四:Kafka API编程--Consumer端开发目标五:Kafka API编程--整合Flume完成实时数据采集htt…
flume 进阶 Ganglia 部署(十二)
规划安装
hadoop100: web gmetad gmod epel-release hadoop101: gmod epel-release hadoop102: gmod epel-release
安装
三台都安装
sudo yum -y install epel-releasesudo yum -y install ganglia-gmond在hadoop100安装
sudo yum -y install ganglia-gmetadsudo yum -y i…
Hadoop日志系统知识
[b][colorgreen][sizex-large]hadoop日志系统中的日志收集模块,在如今比较流行的以及开源具有代表性的有facebook的scribe,apache的chukwa,linkedin的kafka,以及非常优秀的cloudrea的flume,在1.x的hadoop生态系统中&am…
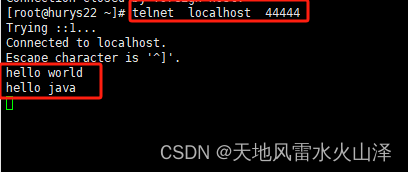
二百零四、Flume——登录监听窗口报错Ncat: bind to :::44444: Address already in use. QUITTING.
一、目的
Flume安装好后测试开启监听窗口44444,结果报错Ncat: bind to :::44444: Address already in use. QUITTING.
二、报错详情
Ncat: bind to :::44444: Address already in use. QUITTING.
三、报错原因
经过分析发现,44444窗口已经被占用
[…
Flume面试题及参考答案
在大数据领域,Flume是一个不可或缺的工具,它负责可靠地收集、聚合和移动大量日志数据。作为一名大数据架构师,掌握Flume的工作原理和最佳实践对于构建高效的数据处理流水线至关重要。本文将深入探讨一系列Flume面试题,并提供详尽的参考答案,以帮助读者在面试中表现出色,并…

一万字完整总结Flume
一、Flume介绍
1.1 前言 官网:http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#kafka-source Flume最早是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统(其中Logstash也是日志采集的一…

二百一十二、Flume——Flume实时采集Linux中的目录文件写入到HDFS中(亲测、附截图)
一、目的
在实现Flume实时采集Linux中的Hive日志写入到HDFS后,再做一个测试,用Flume实时采集Linux中的目录文件,即使用 Flume 监听Linux整个目录的文件,并上传至 HDFS中
二、前期准备
(一)安装好Hadoop、…
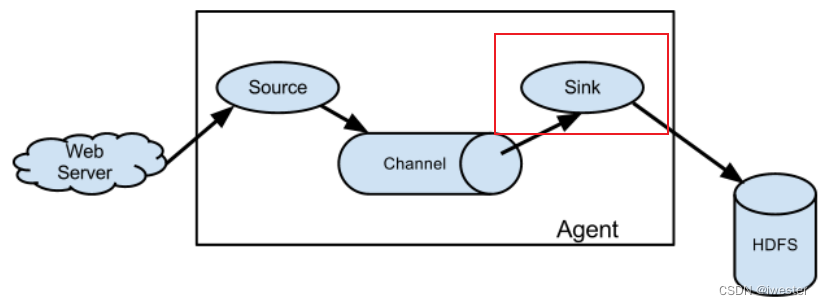
Flume系列:Flume Sink使用
目录
Apache Hadoop生态-目录汇总-持续更新
1:HDFS Sink
HDFS小文件的处理
HDFS存入大量小文件的影响:
HDFS小文件处理:
2:logger Sink
3:写入Kafka - 可以使用kafka channel代替 Apache Hadoop生态-目录汇总-持…
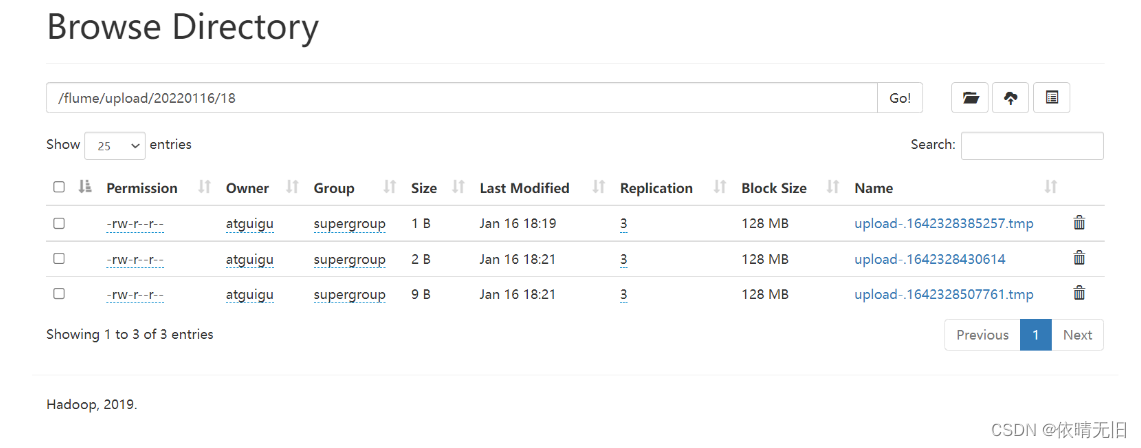
Flume基础知识(五):Flume实战之实时监控目录下多个新文件
1)案例需求: 使用 Flume 监听整个目录的文件,并上传至 HDFS 2)需求分析: 3)实现步骤: (1)创建配置文件 flume-dir-hdfs.conf
创建一个文件
vim flume-dir-hdfs.conf
…

Flume架构及核心组件
Flume架构及核心组件 1)Source 收集 2)Channel 聚集 3)Sink 输出 channel相当于一个通道,类似于一个数据的缓存池,提供一个数据临时存放的地方。在操作系统层面,写数据到磁盘,先会把数据写到内存…
大数据开发之电商数仓(hadoop、flume、hive、hdfs、zookeeper、kafka)
第 1 章:数据仓库
1.1 数据仓库概述
1.1.1 数据仓库概念
1、数据仓库概念: 为企业制定决策,提供数据支持的集合。通过对数据仓库中数据的分析,可以帮助企业,改进业务流程、控制成本,提高产品质量。 数据…
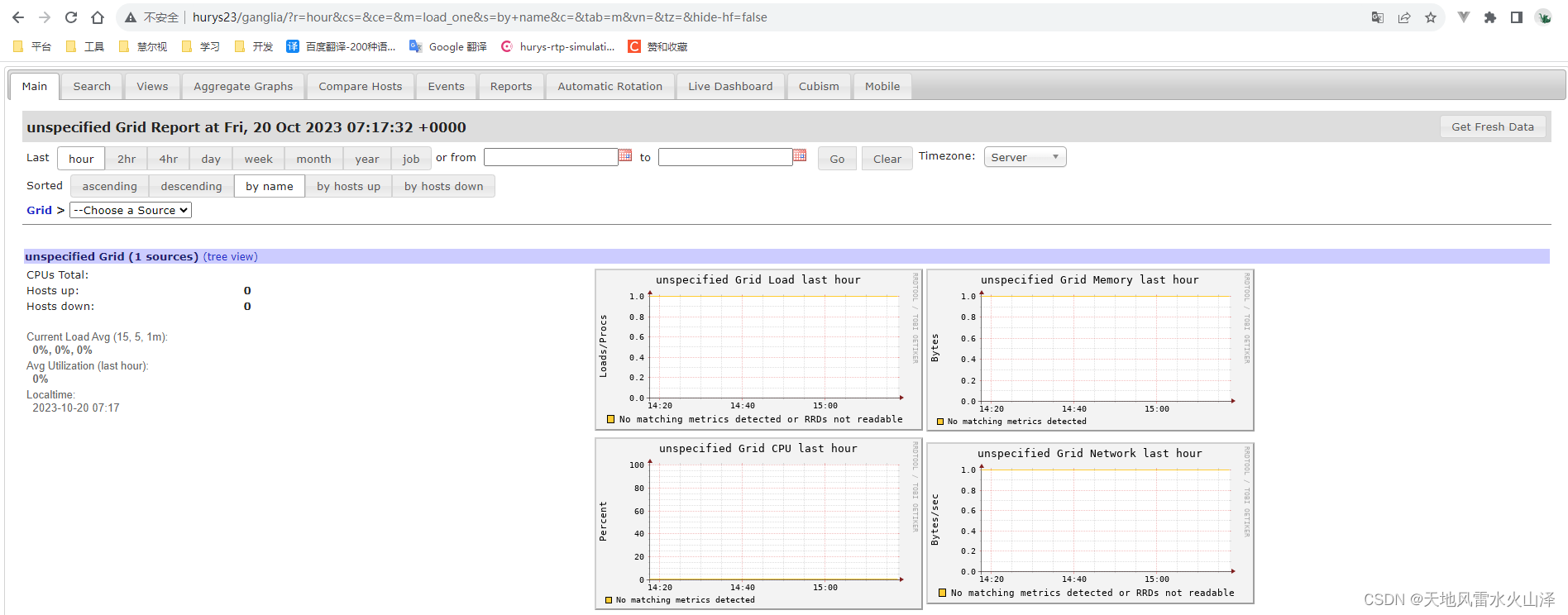
一百九十二、Flume——Flume数据流监控工具Ganglia单机版安装
一、目的
在安装好Flume之后,需要用一个工具可以对Flume数据传输进行实时监控,这就是Ganglia
二、Ganglia介绍 Ganglia 由 gmond、gmetad 和 gweb 三部分组成。 (一)第一部分——gmond gmond(Ganglia Monitoring Da…
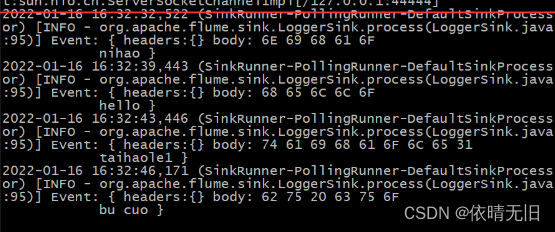
Flume基础知识(三):Flume 实战监控端口数据官方案例
1. 监控端口数据官方案例 1)案例需求: 使用 Flume 监听一个端口,收集该端口数据,并打印到控制台。 2)需求分析: 3)实现步骤: (1)安装 netcat 工具
sudo yum …
Flume入门监控端口数据官方案例
Flume安装部署
相关地址
Flume官网地址:http://flume.apache.org/文档查看地址:http://flume.apache.org/FlumeUserGuide.html下载地址:http://archive.apache.org/dist/flume/
安装
将apache-flume-1.9.0-bin.tar.gz上传到linux的/opt/s…